

| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- 시간적 일관성
- 일론 머스크
- ai 챗봇
- 휴머노이드 로봇
- 확산 모델
- 강화학습
- 오픈AI
- 인공지능
- 오블완
- 자연어 처리
- PYTHON
- 멀티모달
- LLM
- LORA
- 메타
- 트랜스포머
- 실시간 렌더링
- OpenAI
- 티스토리챌린지
- gaussian splatting
- 오픈소스
- AI
- 우분투
- AI 기술
- OpenCV
- 강화 학습
- tts
- 딥러닝
- ChatGPT
- 생성형AI
- Today
- Total
AI 탐구노트
Janus : 이미지, 텍스트를 동시에 이해하고 생성하는 모델 본문

Janus는 이미지와 텍스트를 동시에 이해하고 생성할 수 있는 모델입니다.
기존 멀티모달 모델은 하나의 이미지 인코딩 방식을 이해와 생성에 모두 사용했습니다. 그런데 사실 이 두 작업이 요구하는 정보가 다릅니다. 이미지를 이해하는 작업은 이미지 속의 사물이나 장면을 분석해서 높은 수준의 의미를 추출해야 하고, 생성 작업은 이미지의 세부적인 부분을 그리거나 표현해야 합니다. 그러다보니 하나의 인코딩 방식으로 두 작업을 모두 수행하게 되면 성능이 떨어지는 문제가 있었습니다.
Janus는 시각적 인코딩을 이미지 이해용과 생성용 두 가지로 분리했습니다. 이 두 인코더를 하나의 통합된 Transformer 구조 안에서 결합해, 작업에 맞는 것을 각각 사용할 수 있도록 했고, 이 덕분에 두 작업 간의 충돌을 줄이고 성능을 향상시킬 수 있게 되었습니다.

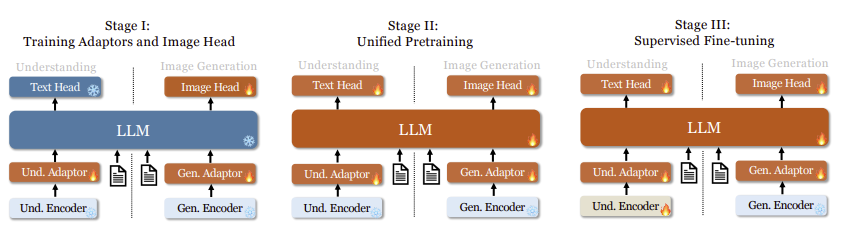
Janus는 아래 그림에서처럼 세 가지 단계 학습 절차를 거칩니다.
- 1단계(초기학습) : 모델이 이미지와 텍스트 간의 관계를 학습하도록 하고 기본적인 이미지 생성 능력을 익히도록 함
- 2단계(통합 사전 학습) : 여러 유형(이미지, 텍스트 등)의 데이터로 학습해서 모델이 다양한 멀티모달 작업을 수행할 수 있게
- 3단계(지도 학습 튜닝) : 사용자의 지시나 대화에 따라 더 잘 응답할 수 있도록 추가적인 학습을 진행함
그 결과, 다음과 같이 다양한 벤치마크에서 SOTA를 능가하는 성능을 보여주고 있습니다.

Janus의 특징은 다음과 같이 요약될 수 있습니다.
- 멀티 모델 통합 : 하나의 모델로 이미지와 텍스트를 동시에 이해하고 생성할 수 있음
- 유연성 : 이미지 이해, 이미지 생성을 상황과 목적에 맞춰 사용할 수 있음
- 확장성 : 기본 구조가 간단해 추가적인 입력방식을 더 쉽게 통합할 수 있음
Janus는 그리스 신화에서 문을 지키는 문지기 역할을 하는 신으로, 앞/뒤로 두개의 얼굴을 가지고 있어 단순히 시간의 흐름을 나태내는 것에 그치지 않고 문을 열고 닫는 순간이나 공간의 경계 등 이중적인 개념을 포괄해서 상징합니다. 이 이름처럼 모델 Janus는 텍스트, 이미지 등 다양한 형태의 입력 데이터를 통합적으로 처리할 수 있는 능력을 지니고 있습니다. 단일 데이터 유형에 국한되지 않고 여러 유형의 데이터를 함께 해석함으로써, 보다 풍부하고 정확한 맥락을 제공할 수 있게 되는 것이죠. 그런 면에서 이름을 참 잘 지었다는 생각이 들었습니다. 역시 첫 임팩트는 이름에서부터 시작하는 것 같습니다!
'AI 기술' 카테고리의 다른 글
| Mochi 1 : 오픈소스 라이선스의 고품질 비디오 생성 모델 (4) | 2024.10.24 |
|---|---|
| OmniGen : 이미지 생성, 이해를 위한 통합 모델 (0) | 2024.10.24 |
| LLM의 자기 성찰과 내성 학습 가능성 증명 (1) | 2024.10.21 |
| 아이콘, 로고, 픽토그램 제공 서비스 조사 (8) | 2024.10.18 |
| F5-TTS : 흐름 매칭을 이용한 유창한 TTS 모델 (0) | 2024.10.16 |



