

| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- 확산 모델
- 오블완
- AI
- 오픈AI
- OpenCV
- LORA
- XAI
- ChatGPT
- 우분투
- ai 챗봇
- 시간적 일관성
- 멀티모달
- 실시간 렌더링
- 오픈소스
- 티스토리챌린지
- LLM
- 일론 머스크
- OpenAI
- 딥러닝
- gaussian splatting
- 메타
- 인공지능
- 생성형AI
- 휴머노이드 로봇
- tts
- 강화 학습
- PYTHON
- 트랜스포머
- AI 기술
- 자연어 처리
- Today
- Total
AI 탐구노트
Mochi 1 : 오픈소스 라이선스의 고품질 비디오 생성 모델 본문

Mochi 1은 Genmo라는 곳에서 만든 SOTA 오픈소스 비디오 생성 모델로 지시어에 충실한 모션과 영상 재현을 특징으로 하고 있습니다. Mochi 1는 일본어로 찹쌀떡이죠. 흠... AI 모델에 동물이름을 주로 사용하는가 싶었는데 이제는 음식이름도 등장하네요. ^^
Genmo라는 곳은 소개에 따르면 전직 구글러들이 창업한 곳이라고 하며 아직은 소수에 펀딩과 채용을 진행 중이라고 합니다.
Mochi 1의 특징
1.라이선스 정책
Mochi 1의 가장 큰 특징으로 꼽으라면 Apache 2.0 라이선스를 따른다는 것입니다. 개인 및 기업이 상업적으로 사용할 수 있게 풀어놓은 것이죠. 흠... 이 정도 고품질 영상을 만들어 낼 수 있는 모델을 이렇게 푼 사례가 언제 있었더라... 개인 크리에이터 입장에선 복 받으세요~ 할 내용인 것 같습니다.
2.프롬프트 준수 영상 생성
제시된 텍스트 프롬프트에 정확하게 일치하는 비디오를 생성합니다. 영상 생성 시 시행착오를 많이 하게되는 것은 사용자가 제시한 내용과 영상이 다소 생뚱맞게 달라지는 부분들이 많이 나온다는 것인데 그런 부분들이 최소화될 수 있다는 것은 좋은 소식이죠.
3.영상 생성 효율성 향상
비대칭 설계를 통해 메모리 사용을 줄이고 영상 생성의 효율성을 높였습니다. 아키텍처 설명 부분에서 좀 더 소개하겠습니다.
Mochi 1 아키텍처
아직 논문이 공개된 상태가 아니라 상세한 내용을 알 순 없고 블로그에 올라온 소개글을 기준으로 보겠습니다.
1.비대칭 확산 변환기
Mochi 1은 100억 개의 매개변수를 갖춘 비대칭 확산 변환기(Asymmetric Diffusion Transformer, AsymmDiT) 구조를 사용하고 있습니다. 비대칭이라는 말은 텍스트와 비디오 정보를 다루는 방식에 대한 것인데, Mochi 1은 텍스트 정보는 간소화 처리하고 비디오 시각적 부분에 더 많은 자원을 투입하는 방식을 채택했습니다. 이렇게 함으로써 비디오 움직임과 디테일이 더 자연스러워진다고 하네요.
2.비디오 데이터 압축
비디오 데이터(시간적, 공간적 부분 둘 다)를 압축해 훨씬 작은 크기 (128배 작게...)로 변환해서 메모리 사용량을 줄이고 연산 처리를 더 빠르게 합니다.
3.3D 주의 매커니즘 적용
2D이미지+텍스트를 한번에 처리하는 다른 모델과 달리 3D로 확장된 비디오의 모든 프레임을 동시에 이용합니다. 장면 간의 일관성 보장을 위해서겠죠...
4.RoPE (회전 위치 임베딩)
비디오 프레임의 순서를 더 잘 이해할 수 있도록 각 프레임의 위치 정보를 학습하며 비디오의 시간적 흐름을 좀 더 자연스럽게 표현합니다.
Mochi 1의 제약 사항
1.해상도 지원 범위
현재 공개된 버전은 480P (720x480) 해상도의 영상을 지원합니다. 연말에는 HD(1920x1080) 수준을 지원하는 모델을 공개할 예정이라고 합니다. 영상 생성 후 프레임 별 혹은 영상 자체에 업스케일을 해주게 되면 그 전에라도 고품질의 영상을 만들 수는 있겠습니다.
2.영상 왜곡 가능성
극단적으로 움직임이 큰 경우에는 영상 왜곡이 일부 발생하 수 있다는 것입니다. 아휴... 그 정도야, 뭐 ^^
3.Playground에 걸린 윤리규정
나머지 제약사항은 Playground에 제법 센 윤리규정을 적용하고 있다는 것입니다. 한마디로 물의를 일으킬만한 영상을 만들 순 없다... 라는거죠. 그것도 괜찮습니다. Apache 라이선스인데요 뭐. ^^
4.하드웨어 요구사항
이 모델을 실행하려면 최소 4개의 H100 GPU가 필요하답니다. H100이 80GB VRAM을 가지고 있으니 320GB 가량의 GPU 메모리를 쓴다는 얘기인가요... 헉... 그런 얘기를 왜 이제서야... 이 때문에 저도 로컬에 설치해 보려고 했다가 나중에서야 깨갱하면 손을 들었답니다. T^T
Mochi 1 체험 방법
Mochi 1은 HuggingFace에 공개한 가중치, 아키텍처를 이용해서 로컬에 설치해서 해 볼 수도 있고, 환경 구성이 어려운 경우, Genmo가 공개한 클라우드 상의 놀이터(Playground)에서 영상 생성을 직접 해 볼 수 있습니다. 현재도 사람들이 테스트로 생성한 영상들이 공유 되어 있습니다. Playground 링크는 다음과 같습니다.
Genmo. The best open video generation models.
Genmo trains the world's best open video generation models. Create incredible videos with AI at Genmo
www.genmo.ai
이곳에는 이미 많은 사람들이 생성한 비디오 영상이 존재합니다. 흠... 역시 발빠른 사람들이 많군요.
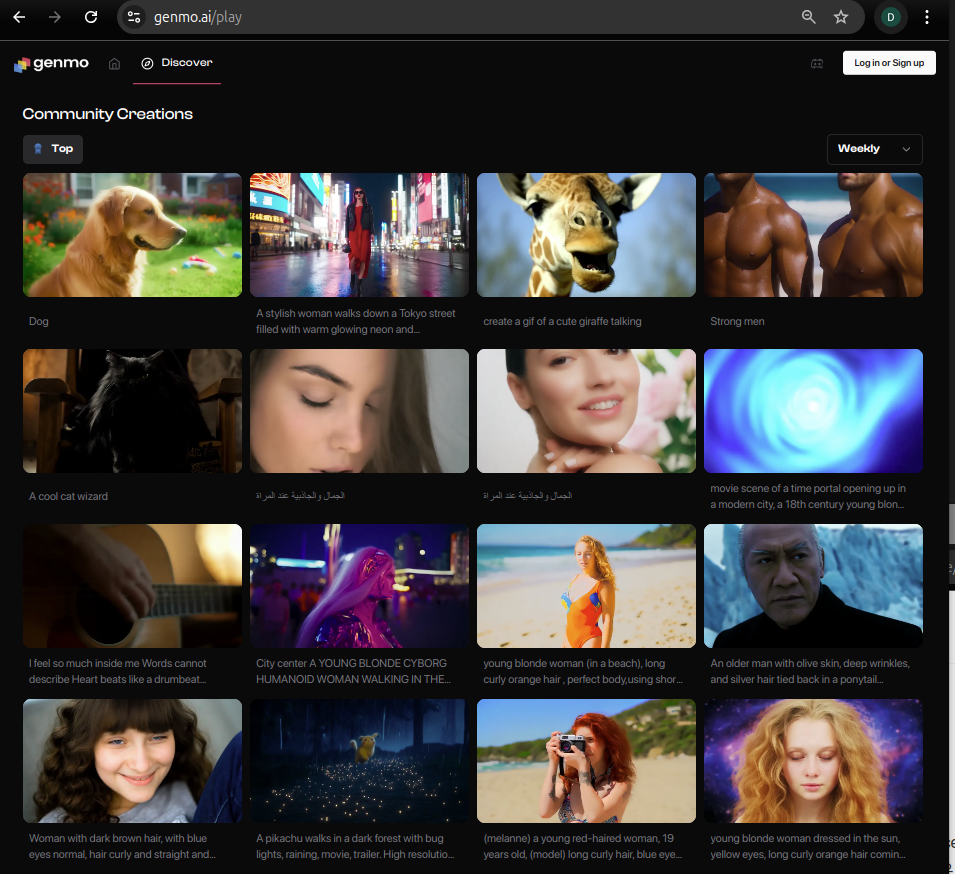
나도 한 번 테스트를...
저도 프롬프트를 다음과 같이 해서 Playground에서 영상을 하나 생성해 봤습니다. 아무래도 시도하려는 사람들이 많다보니 줄 서야 하고 GPU 자원이 부족하면 대기하거나 튕기거나 하는 상황도 있었습니다. 여튼 인내심을 가지고 기다려서 생성을 해 보니 다음과 같은 멋진 영상이 만들어지네요.
텍스트 프롬프트
A young woman wearing a hat is graffitiing the word 'Welcome' on the wall.
생성된 영상
AI를 이용해 재미난 이미지, 영상, 그리고 이것들을 결합한 장난감이나 서비스가 무지무지 많이 쏟아질 것 같습니다. 그런 서비스의 가격 또한 점점 더 이전에 비해서 훨씬 낮게 책정되겠죠. 사람들의 생활이나 업무 효율이 크게 증대되는 동시에 그만큼 사라지는 직업들도 속속 나타나게 될 겁니다. 그래도 지금은 즐겨야겠습니다. 암울하게 지낸들 올 미래가 안 오지는 않으니까요. ^^
'AI 기술' 카테고리의 다른 글
| Waffle : UI 디자인을 HTML 코드로 바꿔주는 기술 (2) | 2024.11.02 |
|---|---|
| MrT5 : 바이트 수준 언어 모델을 위한 동적 토큰 병합 (2) | 2024.10.31 |
| OmniGen : 이미지 생성, 이해를 위한 통합 모델 (0) | 2024.10.24 |
| Janus : 이미지, 텍스트를 동시에 이해하고 생성하는 모델 (1) | 2024.10.21 |
| LLM의 자기 성찰과 내성 학습 가능성 증명 (1) | 2024.10.21 |



