

| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- 우분투
- 오픈소스
- 생성형 AI
- AI
- 시간적 일관성
- LLM
- 확산 모델
- 오픈AI
- tts
- ubuntu
- 트랜스포머
- OpenAI
- OpenCV
- 일론 머스크
- 휴머노이드 로봇
- PYTHON
- Stable Diffusion
- AI 기술
- LORA
- 오블완
- 생성형AI
- 3d 재구성
- 강화 학습
- 메타
- 딥러닝
- 코딩
- 실시간 렌더링
- 티스토리챌린지
- 다국어 지원
- 인공지능
- Today
- Total
AI 탐구노트
TryOffAnyone : 입고 있는 옷을 펼쳐진 이미지로 생성하는 모델 본문

패션 산업은 AI 및 컴퓨터 비전 기술을 활용하여 소비자 경험을 혁신하고 있습니다. 특히, 온라인 쇼핑몰에서는 개인화된 상품 추천과 가상 착용 시스템을 제공하며, 고객의 구매 결정을 돕는 데 중점을 둡니다. 그러나 현재 많은 플랫폼에서 모델이 착용한 의류 사진만 제공되며, 평면(또는 타일) 형태로 전시된 의류 이미지는 거의 찾아볼 수 없습니다. 이는 사용자 경험을 개선할 수 있는 핵심 데이터의 부족을 의미합니다.
기존의 평면 의류 이미지를 얻는 방법은 시간과 비용이 많이 드는 반면, 이미지 생성 기술은 이를 자동화하여 효율성을 높일 수 있는 가능성을 제시합니다. 특히, 딥러닝 기반 모델인 GAN(생성적 적대 신경망)과 LDM(잠재 확산 모델)이 주목받고 있습니다. 이 논문에서 소개된 TryOffAnyone 모델은 LDM을 기반으로 하여 모델 착용 이미지를 평면 의류 이미지로 변환하는 새로운 방법을 제안합니다. 이 모델은 단순화된 네트워크 설계를 통해 고품질 결과물을 생성하는 동시에 학습 비용을 크게 줄이는 데 성공했습니다.
LDM (Latent Diffusion Model) : 이미지를 더 작은 데이터로 압축한 뒤, 그 데이터를 바탕으로 이미지를 만드는 기술을 의미합니다. 달리 비유하면 '복잡한 그림을 작은 스케치로 요약하고, 그 스케치를 점점 더 세밀하게 그려서 원래 그림을 재현하는 방법'과 비슷합니다.
기존 GAN 기반 기술의 한계점
기존 GAN 기반 이미지 생성 기술은 다음과 같은 한계를 지닙니다.
- 훈련 불안정성 : GAN 모델은 학습 과정에서 불안정성을 겪으며, 결과적으로 일관성 없는 결과물을 생성할 수 있습니다.
- 복잡한 구조 : GAN 기반의 네트워크는 고품질 이미지를 생성하기 위해 대규모 데이터와 높은 계산 비용이 필요합니다.
- 세부 정보 손실 : 기존 모델은 복잡한 의류 패턴과 텍스처를 정확히 재현하는 데 어려움을 겪습니다.
TryOffAnyone의 접근 방식
TryOffAnyone은 Stable Diffusion v1.5 모델을 기반으로 하여 다음과 같은 접근 방식을 채택했습니다.
- 단계적 간소화 : 모델 구조를 단일 단계의 U-Net 기반 아키텍처로 단순화하여 계산 효율성을 높였습니다.
- 의류 마스크 활용 : Segformer를 사용하여 착용 이미지를 분석하고, 특정 의류를 분리하기 위해 마스크를 생성함으로써 모델의 정확도를 향상시켰습니다.
- 선택적 네트워크 훈련 : U-Net의 특정 Transformer 블록만 학습시켜 훈련 파라미터를 약 267.24M으로 줄이는 동시에 성능을 유지했습니다.
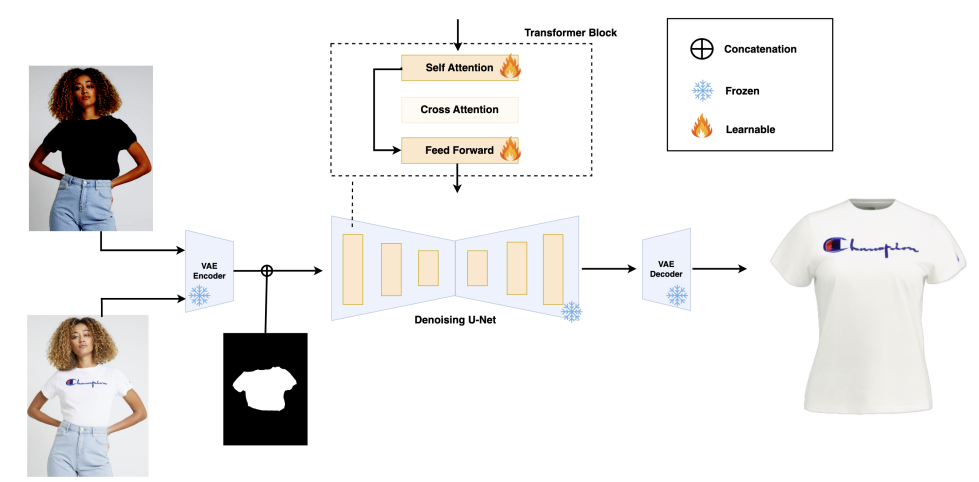
위의 그림은 TryOffAnyone 모델이 이미지를 처리하는 방식을 보여주고 있습니다. 옷 착용 사진과 추출할 옷 영역의 마스크가 입력으로 들어오면 모델은 이미지를 작은 임베딩으로 변환하고 이를 바탕으로 평면 의류 이미지를 생성하게 됩니다.
적용된 세부 기술
1) U-Net 기반 아키텍처
U-Net은 원래 의료 영상 분할을 위해 개발된 모델로, 디코더와 인코더 사이의 스킵 연결을 활용하여 세부 정보를 유지하면서 고품질 이미지를 생성합니다. TryOffAnyone은 이 구조를 확산 모델에 적용하여 고품질의 평면 의류 이미지를 생성합니다.
2) Stable Diffusion 모델의 Fine-tuning
Stable Diffusion은 고차원 이미지 데이터를 잠재 공간(latent space)으로 매핑하는 VAE(Variational Autoencoder)와 확산 과정을 결합하여 고품질 이미지를 생성합니다. TryOffAnyone은 Stable Diffusion 모델을 세부적으로 미세 조정하여 의류 생성 작업에 최적화하였습니다.
3) 의류 마스크 기반 지도
의류 마스크는 사진에서 옷이 있는 부분을 정확히 표시해 주는 도구입니다. 마스크를 사용하면 모델이 '여기가 옷이다'라는 것을 정확히 알 수 있어서, 옷 이외의 배경이나 다른 물건에 신경 쓰지 않고 작업할 수 있습니다. 이 덕분에, 모델은 옷의 무늬나 색상, 모양 같은 세부 정보를 더 잘 살려서 원래 옷과 비슷한 결과를 만들어낼 수 있습니다. 마치 그림을 그릴 때 경계선을 먼저 그려주면 안쪽을 더 깔끔하고 정확하게 채울 수 있는 것과 비슷합니다.
4) Transformer 블록 선택적 훈련
모델은 U-Net의 모든 레이어를 학습시키지 않고 Transformer 블록만 선택적으로 학습하여 훈련 비용을 줄이고 효율성을 극대화합니다. 이를 통해 약 815M개 파라미터를 267M 으로 줄였다고 합니다. 참고로 Transformer 블록은 데이터에서 패턴을 찾고 중요한 정보를 추출하는 데 특화된 부분인데, 여기서는 특히 이미지의 복잡한 구조나 텍스처 같은 세부 정보를 이해하는 데 중요한 역할을 합니다. 비유를 하자면 그림을 그릴 때 모든 부분을 새로 칠하지 않고 그림에서 윤곽선이나 디테일 부분만 세심하게 칠하는 것과 비슷하다고 볼 수 있습니다.
정리하며
TryOffAnyone 모델은 기존 GAN 기반 기술과 비교하여 계산 효율성과 성능 면에서 뛰어난 결과를 보여줍니다. 이는 패션 산업의 가상 착용 시스템 및 개인화된 상품 추천에 혁신적인 변화를 가져올 잠재력을 지니고 있습니다. 향후 연구는 데이터 다양성을 더욱 확장하고, 세부 텍스처 표현을 개선하기 위해 추가 네트워크를 통합하는 방향으로 진행될 수 있습니다.
사람을 찍고 Mask 영역을 지정하면 해당 옷을 추출해서 상품처럼 보여주는 것이라니... 이전까지 주로 찾아봤던 모델이 가상으로 옷을 입혀보는 모델(Virtual-Try-On)이었던터라 사진 속의 사람이 입고 있는 옷을 추출해서 평면에 보여주는 모델은 처음 접했기에 개인적으로는 신선한 경험이었습니다. 그리고, 이런 역할을 하는 앱이나 서비스가 있다면 한번쯤 사람들이 써 보지 않을까 하는 생각도 들었습니다. 만들 실력이 있다면 한번 시도를 해 볼텐데 하고 욕심도 생겼구요. 하지만, 일단은 이런게 있구나 정도로 넘어갑니다. 곧 누군가가 이 기술을 응용한 서비스를 만들어서 내놓을 것을 기대하면서 말이죠. -_-;
4. 참고자료
- 논문) TryOffAnyone: Tiled Cloth Generation from a Dressed Person (링크)
- 코드 (Github)
GitHub - ixarchakos/try-off-anyone: TryOffAnyone: Tiled Cloth Generation from a Dressed Person
TryOffAnyone: Tiled Cloth Generation from a Dressed Person - ixarchakos/try-off-anyone
github.com
- 모델 카드 (HuggingFace)
5. Q&A
Q. TryOffAnyone 모델의 주요 장점은 무엇인가요?
TryOffAnyone은 Latent Diffusion Model을 활용하여 계산 효율성을 높이고, 의류 마스크 기반 지도를 통해 고품질의 세부 텍스처를 정확히 생성합니다.
Q. 의류 마스크는 어떻게 생성되나요?
Segformer 모델을 사용하여 착용 이미지를 분석하고, 특정 의류 영역을 마스킹합니다. 이는 모델의 정확도와 세부 표현력을 강화합니다.
Q. 이 기술은 실제 패션 산업에 어떻게 활용될 수 있나요?
가상 착용 시스템과 온라인 쇼핑몰에서 개인화된 상품 추천 및 고해상도 의류 이미지 생성에 사용될 수 있습니다.
'AI 기술' 카테고리의 다른 글
| LatentSync : 오디오를 기반으로 정확한 입모양을 만드는 AI 기술 (0) | 2025.01.09 |
|---|---|
| Active Bird2Vec : AI 기반 조류 소리 모니터링 (0) | 2025.01.06 |
| VectorPainter : 스타일 참조 기반 텍스트-벡터 그래픽 생성 (0) | 2025.01.01 |
| MV-Adapter : 텍스트로 다각도의 이미지를 쉽게 만드는 기술 (1) | 2024.12.29 |
| Large Concept Models : 문장 단위로 생각하는 인공지능 (1) | 2024.12.27 |



