

| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- 아두이노
- 트랜스포머
- AI
- PYTHON
- 메타
- 티스토리챌린지
- 확산 모델
- LLM
- 생성형 AI
- OpenAI
- LORA
- tts
- OpenCV
- 오블완
- 다국어 지원
- 강화 학습
- 휴머노이드 로봇
- 멀티모달
- 인공지능
- 우분투
- 실시간 렌더링
- 오픈AI
- 오픈소스
- 일론 머스크
- 딥러닝
- 시간적 일관성
- TRANSFORMER
- 이미지 생성
- ChatGPT
- AI 기술
- Today
- Total
AI 탐구노트
Large Concept Models : 문장 단위로 생각하는 인공지능 본문

1. 서론
요즘 인공지능 기술에서 가장 주목받는 것은 대규모 언어 모델(LLM)입니다. 이런 모델은 우리에게 친숙한 챗봇이나 텍스트 생성 서비스 등에 사용되고 있죠. 하지만 이 모델들은 주어진 문장을 단어 하나하나를 예측하면서 작동합니다. 이는 많은 경우에 효과적이지만, 인간처럼 먼저 큰 그림을 그리며 생각하는 것과는 다릅니다. 예를 들어, 긴 문서를 작성하거나 복잡한 문제를 해결할 때 우리는 우선 큰 틀을 세우고, 그 다음에 세부 사항을 채워 넣습니다. 하지만 기존의 LLM은 이런 과정을 제대로 흉내 내지 못하죠.
이 문제를 해결하기 위해 Meta 연구팀은 문장이 하나의 "생각"처럼 작동하는 새로운 모델, 즉 대규모 개념 모델(LCM)을 개발했습니다. 이 모델은 사람들이 생각하는 방식에 더 가까운 방식으로 작동할 수 있도록 언어나 모양(예: 텍스트, 음성)에 상관없이 "문장을 단위로" 추론할 수 있도록 설계되었습니다.
2. 본론
2.1. 기존 방식의 문제점
대부분의 기존 AI 모델은 문장을 구성하는 단어(또는 토큰) 하나하나를 예측하며 작동합니다. 이는 문맥을 이해하는 데는 효과적이지만, 다음과 같은 문제가 있습니다:
- 긴 문서 작성의 어려움 : 모델이 전체 문서를 구성하는 큰 틀을 생각하지 못해, 긴 글에서는 논리적 일관성이 떨어질 수 있습니다.
- 언어 중심적 한계 : 주로 영어에 맞춰 학습되기 때문에, 다른 언어에서는 성능이 낮아질 수 있습니다.
2.2. 새로운 접근 방식: 대규모 개념 모델
LCM은 기존 모델의 문제를 해결하기 위해 문장을 하나의 "개념(Concept)"으로 처리합니다. 즉, 문장을 단순한 단어들의 집합이 아닌, 하나의 생각이나 아이디어처럼 바라보는 것입니다.
- 기본 아이디어 : LCM은 특정 언어가 아닌, 문장이 가진 의미 자체를 다루기 위해 특별한 임베딩 공간(SONAR)을 사용합니다. 이 공간은 문장을 수학적으로 표현하여 AI가 언어에 상관없이 이를 이해하고 조작할 수 있게 만듭니다.
- 작동 방식 : 먼저 입력된 문장을 "개념"으로 바꾼 뒤, 이 개념을 기반으로 AI가 다음에 어떤 문장이 나올지 예측해 결과적으로 여러 언어와 형식(예: 텍스트, 음성)에서 동일한 성능을 낼 수 있습니다.
위 그림에서 왼쪽 그림은 개념(Concept) 공간에서 요약 작업이 어떻게 이뤄지는지를 보여주고 있습니다. 여러 문장을 입력 받아 2개의 문장으로 압축하는 과정입니다. 오른쪽 그림은 LCM의 전체 구조를 나타내는데 입력 문장이 개념 (SONAR 임베딩)으로 변환되고, LCM이 이를 처리한 뒤 출력 개념을 다시 문장으로 변환합니다.
위 그림은 기본 LCM (Base-LCM)의 구조를 나타낸 것으로, LCM이 어떻게 문장 간의 관계를 예측하는지 보여주고 있습니다.
2.3. 주요 기술 요소
2.3.1. SONAR: 언어 독립적인 공간
SONAR는 문장을 언어와 상관없이 숫자로 변환하여 AI가 이를 처리할 수 있도록 합니다. 예를 들어, 영어든 한국어든 같은 의미의 문장은 동일한 "개념(Concept)"으로 처리됩니다. 아래 그림은 음성데이터와 텍스트 데이터를 입력으로 받아 임베딩으로 변환한 후 다시 텍스트로 복원하는 과정을 보여주고 있습니다.
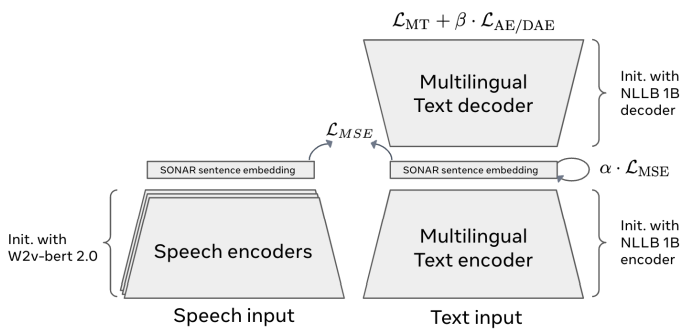
2.3.2. 확산 기반 모델
LCM은 기존 AI가 하나의 답만 찾으려 하는 대신, 다양한 가능성을 고려합니다. 이 과정에서 "확산"이라는 방법을 사용해 노이즈(잡음)를 점차 제거하며 최적의 답을 찾습니다.
2.3.3. 데이터 압축(양자화)
SONAR에서 문장을 처리하는 데이터를 압축하여 더 빠르고 효율적으로 동작할 수 있게 만듭니다.
3. 결론
LCM은 기존 AI의 한계를 넘어서기 위한 중요한 도전입니다. 문장 단위로 생각하고 언어와 무관하게 작동하기 때문에 다국어 환경에서도 뛰어난 성능을 발휘할 가능성이 있습니다. 게다가 긴 글을 작성하거나 여러 언어를 섞어서 사용할 때 유용할 것으로 예상되고 있죠.
Meta는 LLM이 가지는 한계를 넘어서기 위해 새로운 방식의 접근을 계속 시도하고 있는 것처럼 보입니다. 예전 얀 르쿤의 트위터 글(LLM은 AGI로의 길이 아니라는...)을 봐도 그런 것을 짐작할 수 있죠. 아무쪼록 그들의 계속된 시도가 성공하길 기대합니다. 그래야, 제대로 된 AGI를 더 빨리 맞이할 수 있을테니까요...
4. 참고자료
- 'Large Concept Models' 논문 (링크)
- 코드 (Github)
GitHub - facebookresearch/large_concept_model: Large Concept Models: Language modeling in a sentence representation space
Large Concept Models: Language modeling in a sentence representation space - facebookresearch/large_concept_model
github.com
- SONAR 임베딩 기술 자료
5. Q&A
Q. LCM이 기존 AI와 어떻게 다르죠?
기존 AI는 단어를 하나하나 예측하지만, LCM은 문장을 하나의 "생각"처럼 처리하여 더 큰 의미를 고려합니다.
Q. SONAR는 왜 중요한가요?
SONAR는 문장의 의미를 언어와 무관하게 숫자로 변환하여 AI가 더 잘 이해하도록 돕는 핵심 기술입니다.
Q. 이 기술이 왜 필요한가요?
LCM은 긴 문서 작성이나 다양한 언어를 사용하는 작업에서 더 일관되고 효과적인 결과를 낼 수 있습니다.
'AI 기술' 카테고리의 다른 글
| VectorPainter : 스타일 참조 기반 텍스트-벡터 그래픽 생성 (0) | 2025.01.01 |
|---|---|
| MV-Adapter : 텍스트로 다각도의 이미지를 쉽게 만드는 기술 (1) | 2024.12.29 |
| INFP : 대화에 맞춰 움직이는 얼굴을 생성하는 AI 기술 (1) | 2024.12.26 |
| 자동 악보 전사 (Automatic Notes Trascription): 들리는 것을 보이는 것으로 바꾸는 기술 (1) | 2024.12.23 |
| TGH : 긴 볼류메트릭 비디오를 효율적으로 표현하는 시간적 가우시안 계층 구조 (6) | 2024.12.16 |



