

| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- 인공지능
- 실시간 렌더링
- PYTHON
- 강화 학습
- 확산 모델
- ChatGPT
- 멀티모달
- AI
- 메타
- 티스토리챌린지
- OpenCV
- 일론 머스크
- 휴머노이드 로봇
- XAI
- 오픈AI
- LLM
- 자연어 처리
- gaussian splatting
- 트랜스포머
- LORA
- 오블완
- OpenAI
- 딥러닝
- 생성형AI
- 시간적 일관성
- 우분투
- AI 기술
- ai 챗봇
- 오픈소스
- tts
- Today
- Total
AI 탐구노트
STAR: 텍스트-비디오 모델로 실세계 영상 품질 높이기 본문

1. 서론
영상 초해상도(VSR)는 저화질 영상을 고화질로 변환해 디테일을 살리고, 더 선명하게 만드는 기술입니다. 기존의 많은 기술들은 단순한 문제가 있는 영상에서는 성능이 좋았지만, 실제 세상에서 발생하는 복잡한 문제들(압축으로 인한 품질 저하, 노이즈, 흐릿함 등)에는 한계가 있었습니다.
GAN(생성적 적대 신경망) 기반 기술은 디테일을 강화하긴 하지만, 너무 매끄럽게 만들어 자연스러운 느낌이 사라지는 문제가 있었습니다. 최근 확산 모델(diffusion model)이 VSR에 도입되면서 영상의 품질과 디테일 표현은 나아졌지만, 시간적으로 연속된 장면에서 일관성을 유지하는 데에는 여전히 어려움이 있었습니다.
이러한 한계를 해결하기 위해 STAR(Spatial-Temporal Augmentation with Text-to-Video models)라는 새로운 기술이 등장했습니다. STAR는 텍스트-비디오(T2V) 모델을 활용해 더 자연스럽고 일관된 고화질 영상을 만들어냅니다. 이를 위해 두 가지 기술을 도입했는데, 하나는 영상의 세부 정보를 강화하는 모듈(LIEM; Local Information Enhancement Module), 다른 하나는 주파수 기반으로 영상을 세밀하게 학습시키는 손실 함수(DFL; Dynamic Frequency Loss)입니다.
2. 본론
2.1 기존 방식의 문제점
기존 기술은 영상에서 단순히 흐릿한 부분이나 노이즈만 제거하는 데 초점이 맞춰져 있었습니다. 하지만 실제 상황에서는 더 복잡한 문제들이 많습니다. 예를 들어, 동영상에서 한 프레임은 선명해 보이지만 다음 프레임이 갑자기 흐릿해지거나, 영상의 일부가 왜곡되어 보일 수 있습니다. GAN 기술은 이러한 문제를 해결하려 했으나, 결과적으로 디테일이 지나치게 부드러워져서 비현실적인 모습이 되곤 했습니다.
2.2 접근 방식
STAR 모델은 입력된 저화질 영상을 VAE로 처리해 잠재 변수를 생성하고, 텍스트-비디오 모델과 LIEM을 통해 지역 정보와 전체 정보를 조합한 후 마지막으로 DF Loss를 적용해 고품질의 영상으로 복원합니다.

STAR는 텍스트-비디오 모델을 사용해 영상 품질을 높이는 새로운 방법으로 핵심적인 기술은 다음의 두 가지를 들 수 있습니다.
- 지역 정보 강화 모듈(LIEM, Local Information Enhancement Module)
이 모듈은 영상의 세부적인 지역 정보를 더 잘 살리도록 설계되었습니다. 기존 모델이 영상 전체를 한 번에 처리했다면, LIEM은 지역별로 세부 정보를 보완하고, 이를 전체 정보와 결합해 더욱 정교한 결과를 만들어냅니다.

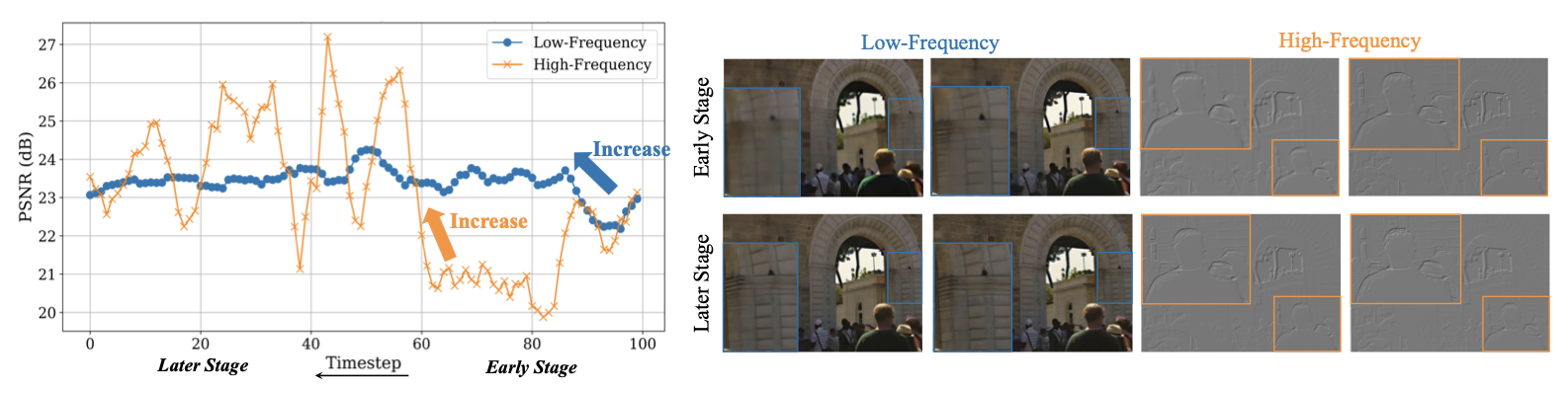
- 동적 주파수 손실(DF Loss, Dynamic Frequency Loss)
DF Loss는 영상을 저주파(구조)와 고주파(세부 디테일)로 나눠 각각의 요소를 적절한 시점에 집중적으로 학습시킵니다. 초기에는 영상의 전반적인 형태와 구도를 복원하고, 이후 디테일한 부분을 채워넣어 결과물을 완성하는 방식입니다.
3. 결론
STAR는 텍스트-비디오 모델과 새로운 기술(LIEM, DF Loss)을 결합해 실세계 영상 초해상도의 품질을 크게 향상시킵니다. 이 기술은 영상의 디테일과 시간적 일관성을 모두 강화했으며, 다양한 실험 결과에서 최신 기술 대비 우수한 성능을 입증했습니다. STAR는 향후 실생활에서 고화질 영상 복원과 같은 분야에 널리 활용될 것으로 기대됩니다.
4. 참고자료
- 프로젝트 사이트
STAR for Real-World Video Super-Resolution
Image diffusion models have been adapted for real-world video super-resolution to tackle over-smoothing issues in GAN-based methods. However, these models struggle to maintain temporal consistency, as they are trained on static images, limiting their abili
nju-pcalab.github.io
- 코드) STAR Github Repository
GitHub - NJU-PCALab/STAR: STAR: Spatial-Temporal Augmentation with Text-to-Video Models for Real-World Video Super-Resolution
STAR: Spatial-Temporal Augmentation with Text-to-Video Models for Real-World Video Super-Resolution - NJU-PCALab/STAR
github.com
- 논문) STAR: Spatial-Temporal Augmentation with Text-to-Video Models for Real-World Video Super-Resolution (링크)
- 소개영상) STAR 소개 영상 (링크)
5. Q&A
Q. STAR는 기존 GAN 기반 모델과 어떤 점에서 차별화되나요?
STAR는 GAN의 평활화 문제(너무 매끄럽게 만들어 자연스러운 느낌이 사라지는 문제)를 해결하며, 텍스트-비디오 모델과 LIEM 및 DF Loss를 통해 더 자연스러운 디테일과 시간적 일관성을 제공합니다.
Q. LIEM이 없을 경우 성능은 어떻게 달라지나요?
LIEM이 없는 경우 지역적 디테일 복원이 어려워져 왜곡 제거 성능이 저하되며, 결과 영상에서 흐릿한 디테일이 발생할 수 있습니다.
Q. DF Loss는 모든 VSR 작업에 적용 가능한가요?
DF Loss는 주파수 기반 학습 전략이 필요한 작업에서 효과적이지만, 구조와 디테일 간 명확한 분리가 어려운 작업에서는 효과가 제한적일 수 있습니다.
'AI 기술' 카테고리의 다른 글
| TransPixar : 투명한 비디오 생성의 새로운 시대 (0) | 2025.01.12 |
|---|---|
| SWITTI: 스케일-와이즈 트랜스포머를 활용한 텍스트-이미지 생성 (0) | 2025.01.11 |
| LatentSync : 오디오를 기반으로 정확한 입모양을 만드는 AI 기술 (0) | 2025.01.09 |
| Active Bird2Vec : AI 기반 조류 소리 모니터링 (0) | 2025.01.06 |
| TryOffAnyone : 입고 있는 옷을 펼쳐진 이미지로 생성하는 모델 (1) | 2025.01.03 |



