

| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- XAI
- 생성형AI
- LLM
- ai 챗봇
- 휴머노이드 로봇
- 시간적 일관성
- ChatGPT
- 자연어 처리
- 딥러닝
- 메타
- gaussian splatting
- OpenAI
- 멀티모달
- OpenCV
- tts
- 트랜스포머
- 강화 학습
- 오픈소스
- AI
- LORA
- 오픈AI
- 티스토리챌린지
- 일론 머스크
- 확산 모델
- PYTHON
- AI 기술
- 인공지능
- 오블완
- 실시간 렌더링
- 우분투
- Today
- Total
AI 탐구노트
SmolDocling: 초소형 비전-언어 모델을 활용한 문서 변환 기술 본문

문서를 디지털 데이터로 변환하는 것은 생각보다 어려운 작업입니다. 특히 PDF 문서는 인쇄에 최적화된 형식이라 내부 내용을 쉽게 분석하기 어렵습니다. 문서에는 텍스트뿐만 아니라 표, 수식, 차트, 코드 같은 다양한 요소가 포함되어 있어 단순한 OCR(광학 문자 인식) 기술만으로 정확한 변환이 어렵습니다.
기존에는 두 가지 방식이 많이 사용되었습니다. 첫 번째는 각 요소를 따로 처리하는 시스템입니다. 예를 들어, OCR 기술로 텍스트를 인식한 후, 별도의 모델이 문서 레이아웃을 분석하고, 또 다른 모델이 표나 수식을 변환하는 방식입니다. 이렇게 하면 비교적 정확한 결과를 얻을 수 있지만, 여러 모델을 조합해야 해서 시스템이 복잡해지고 처리 속도가 느려지는 단점이 있습니다.
두 번째는 대형 AI 모델을 이용하는 방식입니다. 최근 AI 기술이 발전하면서 문서 전체를 한 번에 변환할 수 있는 멀티모달(Multi-modal) AI 모델이 등장했습니다. 이런 모델은 문서의 구조를 이해하고 내용을 변환하는 능력이 뛰어나지만, 크기가 커서 많은 컴퓨팅 자원이 필요합니다. 따라서 일반 사용자들이 쉽게 사용할 수 없는 경우가 많습니다.
이러한 문제를 해결하기 위해 SmolDocling이 개발되었습니다. SmolDocling은 작고 가벼운 AI 모델이면서도 문서 변환 기능이 뛰어납니다. 기존 대형 AI 모델보다 5~10배 작지만, 비슷한 성능을 유지하면서도 훨씬 적은 컴퓨팅 자원으로 작동합니다.
SmolDocling
1) 기존 방식의 문제점
- 여러 개의 모델을 조합하는 방식 : 성능이 높지만 시스템이 복잡하고 최적화가 어렵습니다. 각각의 모델이 따로 학습되기 때문에 하나라도 오류가 나면 전체 변환 과정에 영향을 줍니다.
- 대형 AI 모델을 이용하는 방식 : 뛰어난 성능을 보이지만, 많은 메모리와 연산 능력이 필요해 일반 사용자가 쉽게 사용할 수 없습니다. 또한, 이러한 모델은 종종 불필요한 데이터를 생성하거나 "환각(hallucination)" 현상을 일으켜 정확한 정보를 제공하지 못하는 경우가 있습니다.
이러한 문제점을 해결하기 위해 SmolDocling은 작지만 효율적인 AI 모델로 설계되었습니다.
2) SmolDocling의 접근 방식
SmolDocling은 문서 변환을 위해 비전-언어 모델(Vision-Language Model, VLM)을 활용합니다. 이 모델은 문서 이미지를 입력받아 내용을 분석하고, DocTags라는 새로운 마크업 형식으로 변환합니다.
- DocTags란?
기존 HTML이나 Markdown 같은 형식은 문서의 구조를 완벽하게 표현하지 못하는 경우가 많습니다. SmolDocling은 DocTags라는 새로운 형식을 만들어 문서의 텍스트, 표, 수식, 차트, 이미지 위치 등을 정확하게 저장합니다. - 한 번에 변환
SmolDocling은 OCR, 레이아웃 분석, 테이블 인식 등을 한 모델에서 한 번에 처리합니다. 따라서 여러 개의 AI 모델을 조합할 필요가 없습니다. - 컴퓨팅 비용 절감
기존 대형 모델보다 최대 27배 작기 때문에 연산량이 적고 빠르게 실행됩니다.
3) SmolDocling 아키텍처
문서 이미지는 Vision 인코더를 통해 분석되며, 이 정보는 DogTags 형식으로 변환되며, LLM은 이를 최종 변환해 사용자에게 제공하게 됩니다. 아래 그림은 SmolDocling의 아키텍처를 설명하고 있습니다.

우선 변환을 하고자 하는 문서 이미지(텍스트, 표, 코드, 차트, 수식 등 다양한 요소가 포함된)가 입력으로 들어오면, 비전 인코더(Vision Encoder)를 통해 시각적 특징을 분석하고, 텍스트와 구조를 인식하며 SigLIP이라는 특수한 이미지 인코더를 사용해 문서 내 요소의 위치와 관계를 파악합니다. 그런 뒤 Projection과 Pooling을 통해 시각적 특징(이미지 정보)과 텍스트 데이터가 하나의 형태로 정리되어 최종적으로 LLM에 의해 DocTags 형식으로 문서를 변환합니다. 이렇게 변환된 정보를 기반으로 텍스트, 표, 수식 등을 원본과 유사하게 복원할 수 있습니다.
4) 세부 적용 기술
SmolDocling에는 여러 가지 핵심 기술이 적용되었습니다.
1️⃣ 모델 구조
SmolDocling은 SmolVLM-256M이라는 소형 비전-언어 모델을 기반으로 합니다.
- 비전 인코더(vision encoder) : 문서 이미지를 분석하여 텍스트와 구조 정보를 추출합니다.
- LLM(대형 언어 모델) : 분석된 데이터를 학습하여 문서를 변환하는 역할을 합니다.
2️⃣ DocTags 마크업 형식
SmolDocling은 문서의 내용을 DocTags라는 형식으로 변환합니다. DocTags는 문서의 요소(텍스트, 표, 수식 등)를 태그 형태로 저장하는 방식을 따릅니다.
- 예를 들어, 표는
<table>태그, 제목은<section_header>태그처럼 XML 스타일로 구조화됩니다. - 위치 정보도 포함되어 있어 문서의 원래 레이아웃을 유지할 수 있습니다.
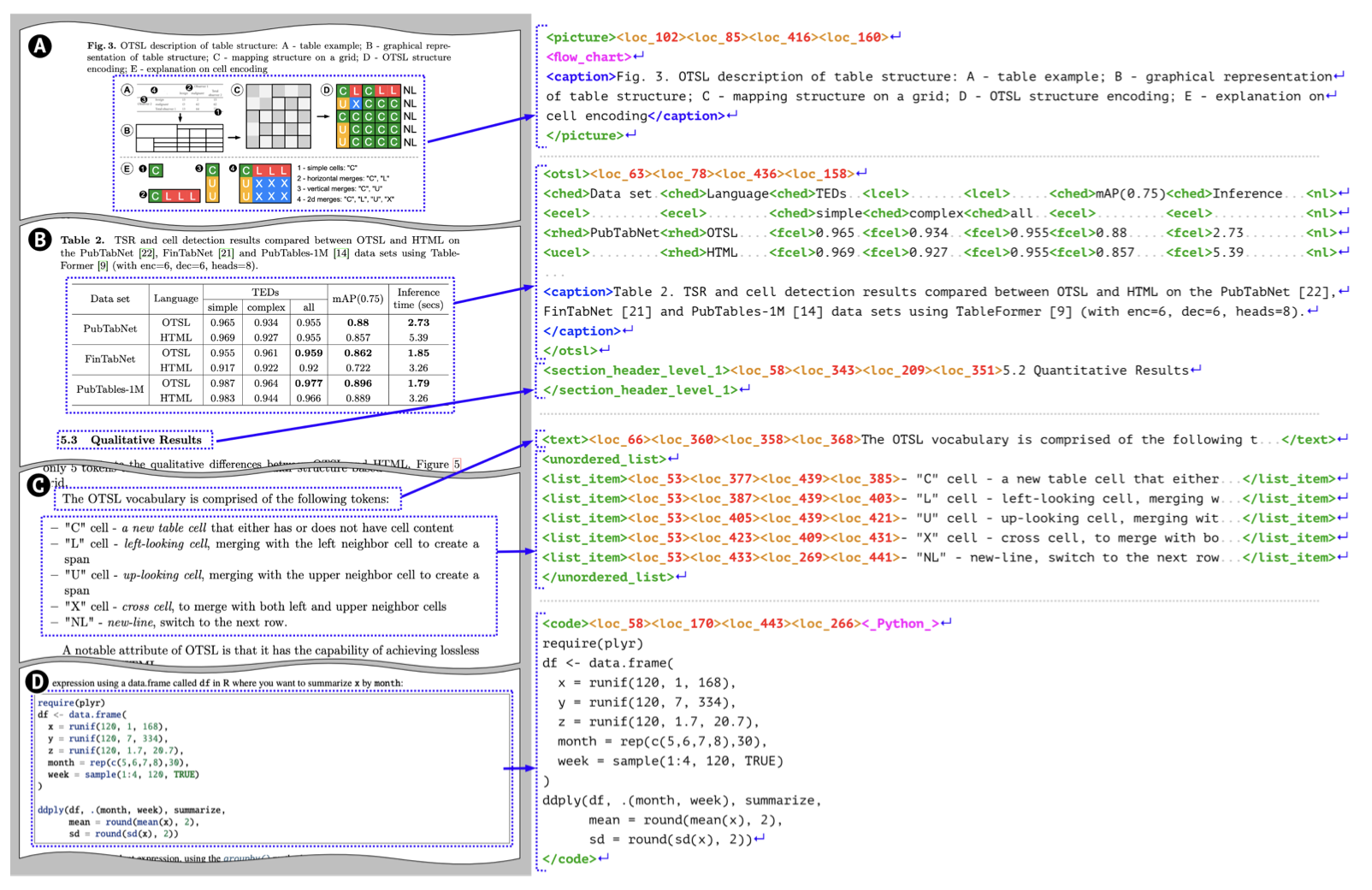
3️⃣ 데이터셋 활용
SmolDocling은 다양한 문서 유형을 학습하기 위해 다음과 같은 여러 공개 데이터셋을 활용했습니다.
- DocLayNet-PT : PDF 문서를 분석하고 텍스트와 레이아웃 정보를 제공하는 데이터셋
- SynthDocNet : 위키백과 내용을 기반으로 합성 문서를 생성한 데이터셋
- PubTables-1M : 표 구조를 학습하기 위한 데이터셋
SmolDocling은 기존의 대형 AI 모델보다 가볍고 효율적인 문서 변환 기술로 하나의 모델로 OCR, 레이아웃 분석, 표 인식을 동시에 수행할 수 있습니다. DocTags라는 새로운 마크업 형식을 활용해 문서의 원본 구조를 보존하며, 기존 대형 모델보다 5~10배 작지만, 비슷한 성능을 유지한다는 장점이 있습니다.
벌써 이 모델을 이용해 스마트폰 온디바이스에서 문서 내용을 읽어내는 앱 예시도 나온 상태입니다. 그만큼 용도에 따른 다양한 활용도 손쉽게 해 볼 수 있는 여지를 준다고 할 수 있겠습니다. 뭔가를 프로토타이핑하기 딱 좋은 기술일 것 같습니다. :-)
참고자료
- 논문) SmolDocling: An ultra-compact vision-language model for end-to-end multi-modal document conversion (링크)
- 데모) Hugging Face Space (링크)
Q&A
Q. SmolDocling은 어떤 문서 유형을 지원하나요?
학술 논문, 비즈니스 문서, 기술 보고서, 특허 문서, 양식(Form) 등 다양한 문서를 변환할 수 있습니다.
Q. SmolDocling이 기존 OCR 모델과 다른 점은 무엇인가요?
단순한 텍스트 변환이 아니라 문서의 구조(레이아웃, 표, 수식, 차트 등)까지 정확하게 변환합니다.
Q. SmolDocling을 활용하면 어떤 장점이 있나요?
대형 AI 모델보다 작고 빠르면서도 높은 성능을 유지합니다. 따라서 개인 사용자나 소규모 기업도 쉽게 사용할 수 있습니다.
'AI 기술' 카테고리의 다른 글
| Personalize Anything : 디퓨전 트랜스포머로 개인화된 이미지 생성하기 (2) | 2025.03.20 |
|---|---|
| ReCamMaster : 하나의 영상으로 카메라 움직임을 자유롭게 바꾸는 기술 (0) | 2025.03.20 |
| Inductive Moment Matching: 빠르고 안정적인 생성 모델 학습 기법 (0) | 2025.03.18 |
| CPR : 고속 이상 탐지를 위한 계층적 패치 검색 기법 (0) | 2025.03.16 |
| MIDI: 단일 이미지에서 3D 장면 생성을 위한 다중 인스턴스 확산 모델 (1) | 2025.03.15 |



