

| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- 인공지능
- 일론 머스크
- PYTHON
- 이미지 생성
- nvidia
- OpenCV
- AI 기술
- 딥러닝
- 트랜스포머
- 오블완
- LORA
- 시간적 일관성
- 오픈AI
- 강화 학습
- TRANSFORMER
- OpenAI
- ubuntu
- 메타
- 아두이노
- 다국어 지원
- 확산 모델
- 티스토리챌린지
- 생성형 AI
- 휴머노이드 로봇
- tts
- LLM
- AI
- 오픈소스
- 우분투
- ChatGPT
- Today
- Total
AI 탐구노트
Invoke : 비주얼 미디어를 위한 전문 크리에이티브 AI 도구 본문

Invoke는 Invoke AI에서 개발한 전문 크리에이터를 위한 AI 편집 도구입니다.
이미지 생성 및 편집 전문 도구
컨텐츠를 만들기 위해 이미지가 필요할 때가 있습니다.
이 경우, Unsplash, Pixabay, Freepik 등과 같이 이미지 제공 사이트를 이용하거나 하죠.
최근에는 생성형 AI의 등장으로 자신이 원하는 이미지를 직접 생성하는 것이 추세가 되고 있습니다.
MidJourney, Stable Diffusion 등 다양한 서비스가 있는데요...
그런 AI를 이용해서 이미지를 생성하고 나서도 완전히 자기 입맛에 맞는 이미지를 구하기는 힘듭니다.
그래서, 다시 편집 전문 도구를 이용해서 부분을 잘라내고 바꾸고 하는 작업들을 하게 되죠.
돌고 돌아 다시 Adobe의 제품으로 갑니다.
Adobe는 이걸 생각하고 자신들의 제품에 위에서 언급한 생성형 AI의 기능을 임베딩해서 서비스하고 있죠.
다른 데 갈 필요가 뭐가 있냐, 여기서 다 해라 이런 의미입니다.
Invoke AI는 바로 이런 부분을 파고든 것 같습니다.
AI를 이용한 이미지 생성부터 세부적인 부분 변경까지 자유자재로 할 수 있는 기능을 제공하고 있기 때문입니다.
게다가 이런 기능들을 로컬 컴퓨터에 설치하는 경우에는 무료로 사용할 수 있으며
Apache 2.0 라이선스를 따르고 있기 때문에 이를 상용으로 사용할 수도 있습니다.
Invoke에 대해 조금 더 들어가 보겠습니다.

위의 화면은 컨트롤 캔버스 혹은 통합 캔버스라고 불리는 저작 도구의 한 장면입니다.
이를 통해 이미지 생성, 편집 등의 기능을 활용할 수 있습니다.
Invoke가 제공하는 기능
- 통합 캔버스 (Unified Canvas) : 이미지 생성, 인/아웃 페인팅, 브러시 도구 등 지원
- 워크플로우 및 노드 : 사용자 정의 가능한 생성 파이프라인 개발이나 공유 지원
- 업스케일 기능, 프롬프트 템플릿 지원
- 관리 기능 : 보드 & 갤러리, 생성 모델, 임베딩 관리 기능
- 백엔드 이미지 생성 모델 : SD1.5, SD2.0, SDXL, Flux.1 등 지원 (ckpt, diffusers 모델 지원)
- 웹서버 + React 기반 UI 제공
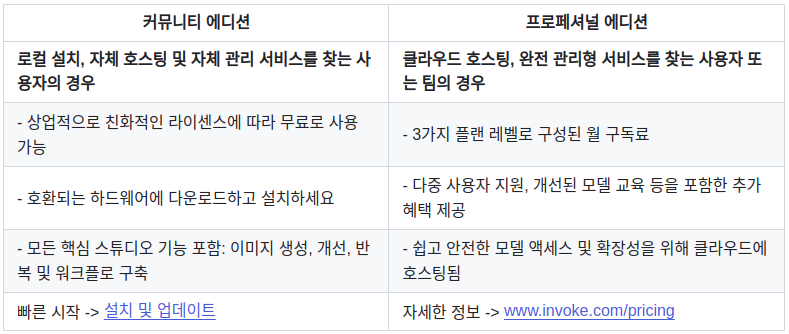
Invoke Community 버전과 Professional 버전 간 차이
아래 도표는 InvokeAI의 github 레포지토리에 있는 비교표입니다.
앞서 무료로 제공된다고 한 것이 커뮤니티 에디션, 유료는 프로페셔널 에디션입니다.
간단하게는 자신의 컴퓨터에 직접 설치해서 사용할 경우에는 무료,
그렇지 않고 클라우드에서 관리형 서비스를 이용할 경우에는 구독료 기반 유료 (3가지 플랜)라는 겁니다.
Community Edtion
로컬에 설치한다고 말씀드렸었죠?
설치 방법은 이곳을 참조하시면 되며 간단하게 몇 가지만 요약해 보면 다음과 같습니다.
직접 설치하지 않고 Docker Container를 이용하는 방법도 있습니다.
1.시스템 요구사항
- GPU : CPU만으로도 가능하다 비추. VRAM 12GB 이상의 GPU 권고
참고) AMD ROCm은 Linux에서만 지원. 불안정 가능성 있음 - 디스크 : SSD 권고, 모델 사이즈에 따라 확장 필요
- Pythorn : 3.11 권고
- CUDA, cuDNN 최신 버전 설치
일단 위의 내용만으로는 현재 제 환경이 다 갖추고 있는 것들이네요. :-)
2.환경 설정
우선 installer를 이곳에서 다운받아 실행합니다.
참고로 installer는 invoke가 설치된 상태에서는 재설치가 아닌 업데이트를 진행한다고 합니다.
# installer 다운로드 및 압축해제
$ wget https://github.com/invoke-ai/InvokeAI/releases/download/v5.0.2/InvokeAI-installer-v5.0.2.zip
$ unzip
$ cd InvokeAI-installer-v5.0.2/InvokeAI-Installer
# installer 실행
$ ./install.sh
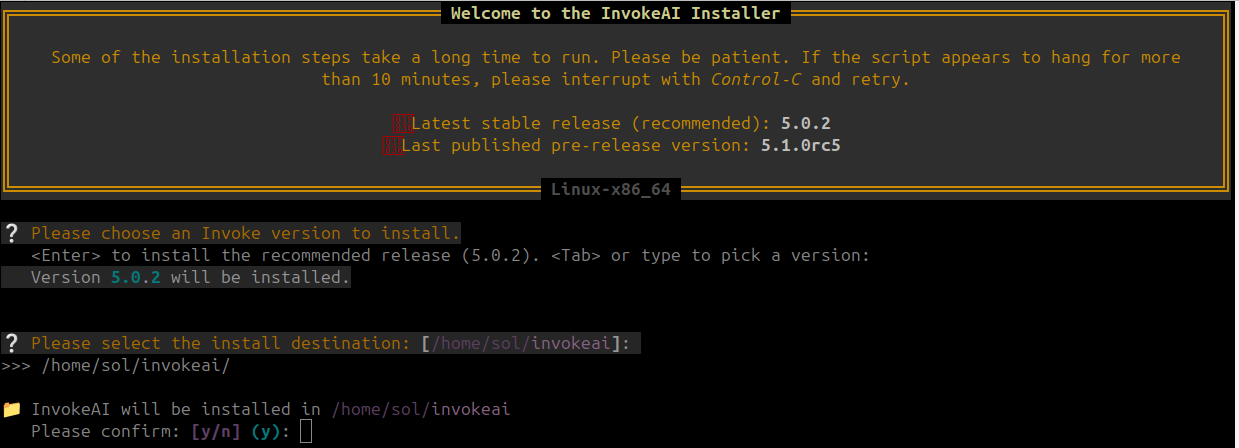
Invoke 설치 버전 및 위치 설정
저는 아래 설치 시 질문에 대해 각각 5.0.2, 기본 위치($HOME/invokeai)로 답했습니다.
3번의 엔터를 눌러서 기본으로 진행한 거죠. ^^;
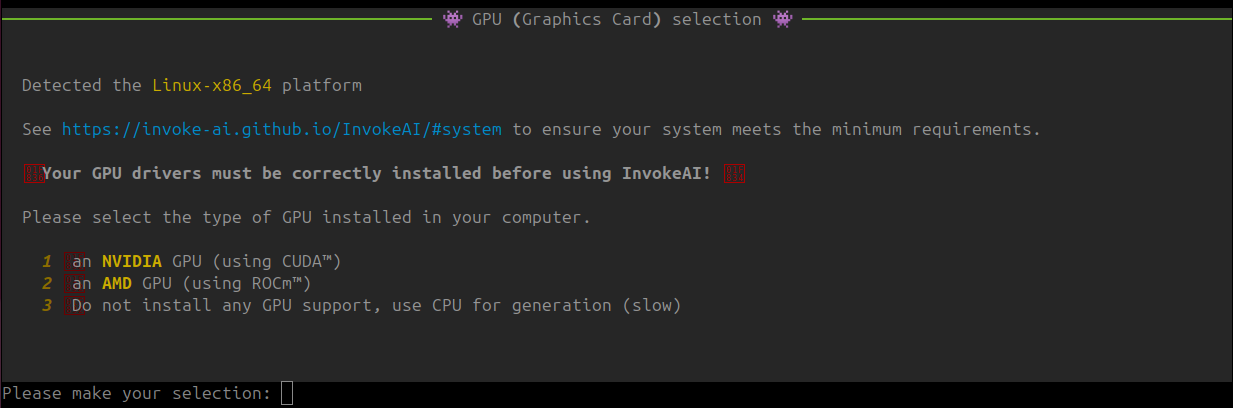
GPU 및 CUDA 설치 확인
저는 CUDA를 사용할 수 있는 환경이어서 '1'을 선택했습니다.
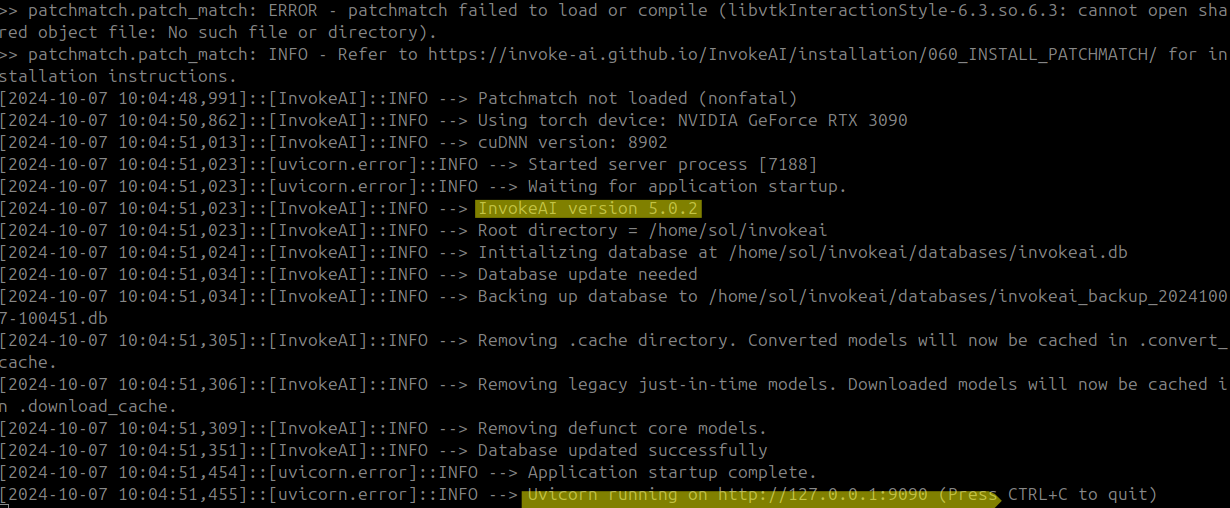
위의 과정을 거치고 나면 설치가 진행되고 아래 내용처럼 설치 완료 메시지가 나옵니다.
nsformers-4.41.1 triton-2.2.0 typer-0.12.5 typing-extensions-4.12.2 tzdata-2024.2 ujson-5.10.0 urllib3-1.26.20 uvicorn-0.28.0 uvloop-0.20.0 watchfiles-0.24.0 wcwidth-0.2.13 websockets-13.1 werkzeug-3.0.4 wrapt-1.16.0 wsproto-1.2.0 xformers-0.0.25.post1 xxhash-3.5.0 yarl-1.13.1 zipp-3.20.2
*** Installation Successful ***
To start the application, run:
/home/sol/invokeai/invoke.sh
추가 모듈 설치
리눅스, Mac 사용자는 아웃페인팅을 지원하는 패키지(Pypatchmatch)를 추가로 설치해야 한답니다. (링크)
이 패키지는 Opencv가 있어야 하므로 사전에 아래와 같이 설치해 주고 진행합니다.
# pypatchmatch 설치를 위한 apt 패키지 사전 설치
$ sudo apt update
$ sudo apt install build-essential
$ sudo apt install python3-opencv libopencv-dev
# pypatchmatch python 패키지 설치
$ pip install pypatchmatch
그런데...
가능하면 Conda의 가상환경 상에서 진행하시기 바랍니다.
기존 설치되어 있던 환경이 다 뒤죽박죽될 수 있기 때문입니다. 다행히 제 경우에는 문제는 없었습니다.
Invoke에서의 이미지 생성 테스트
1.Invoke 실행
Invoke 실행을 해 봅니다.

저는 이미지 생성을 해 볼 것이라 선택 사항 가운데 1번을 선택했습니다.
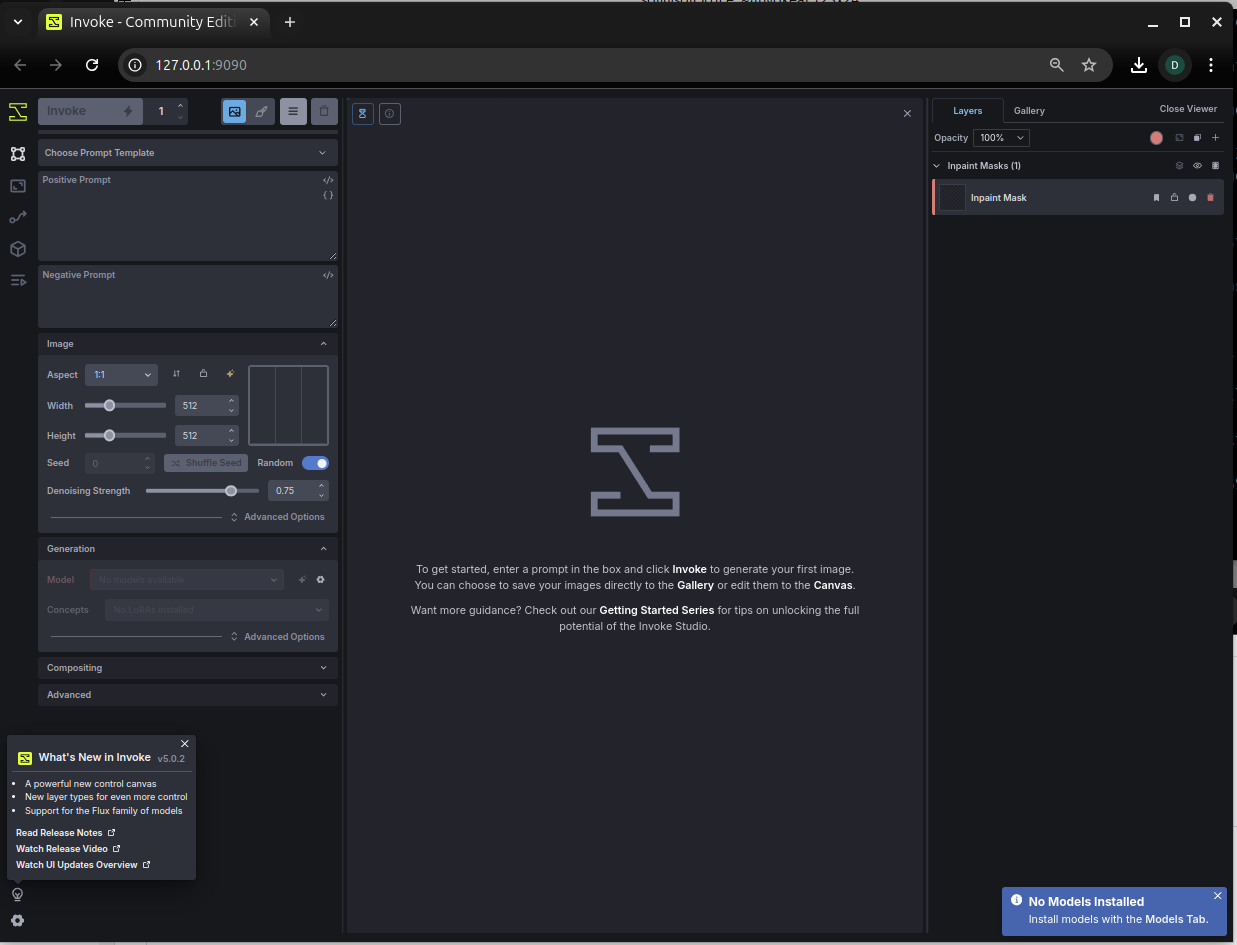
도구가 정상적으로 기동되면 위 이미지처럼 접속 가능한 로컬 주소가 표시됩니다.
해당 URL을 브라우저로 열어보면... 짜잔~하고 Invoke의 통합 캔버스 화면이 뜹니다.
2.모델 설치
백엔드 모델을 추가하는 방법은 다음과 같은 것이 제공됩니다. (붉은 색이 제 권장입니다. ^^;)
- Starter Models에서 선택 설치
- URL 또는 로컬 경로 (파일 선택)
- HuggingFace Rep Id 이용
- (로컬) 폴더 스캔
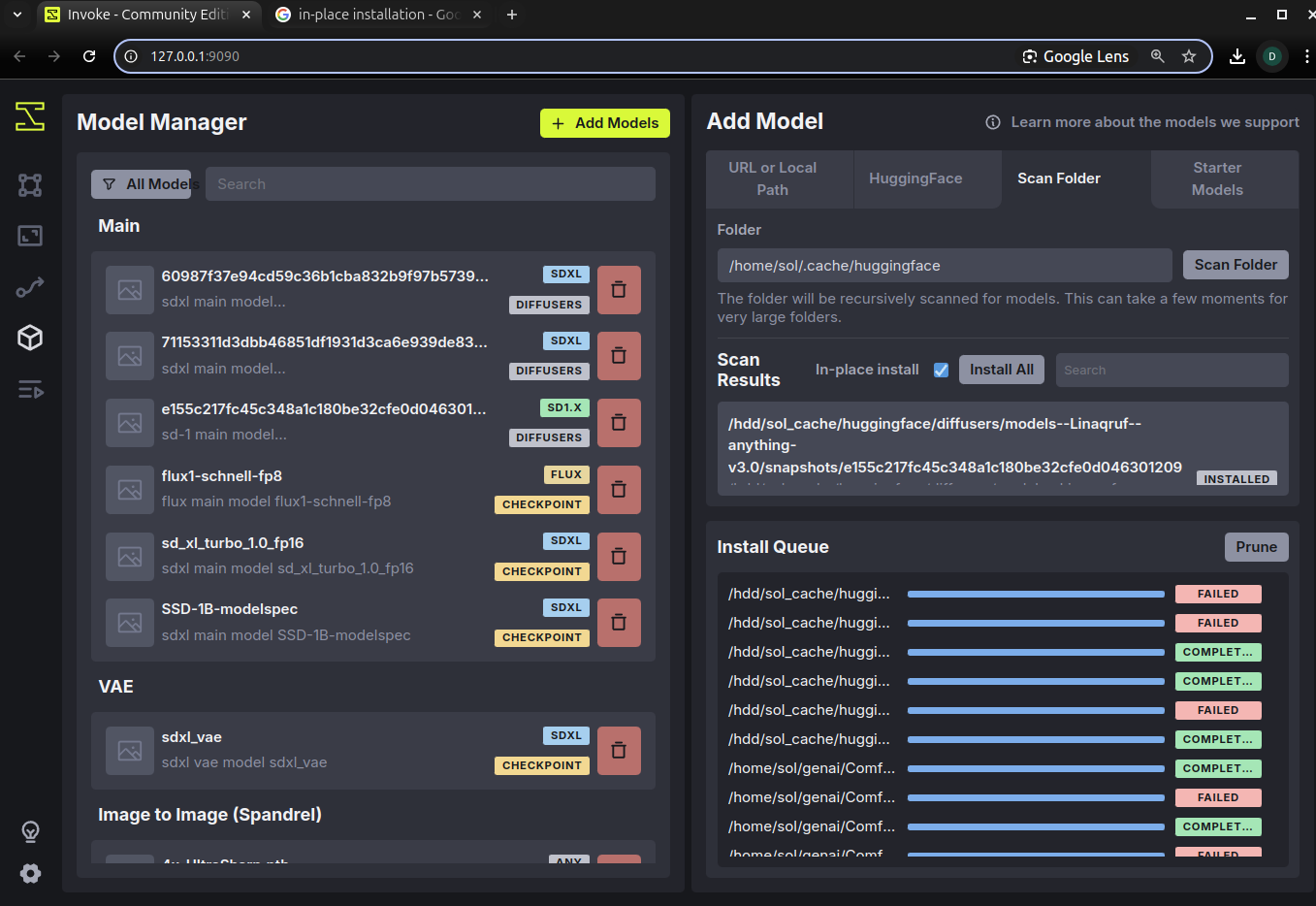
시행착오-1. 모델 설치 방식
제 경우, Flux.1 등 몇가지 테스트 하느라 로컬에 다운받았던 가중치 파일들이 있어
'폴더 스캔'을 이용해서 추가해 봤는데 아래와 같이 오류가 나는 것들이 있었습니다.
ComfyUI에서는 사용하고 있는 모델이므로 가중치 파일 자체의 문제는 아닌 것 같고...
Invoke가 셋트로 관리하는 방식이 따로 있나 봅니다.
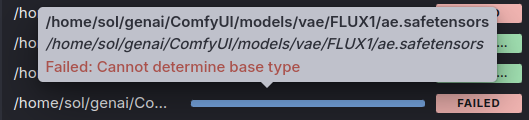
시행착오-2. 모델로 ComfyUI에서 사용하던 Flux.1 가중치 선택
Flux.1을 이용해 이미지 생성을 하려고 했는데 다음과 같은 오류가 발생했습니다.
내용 상으로는 Flux.1에서 필요로 하는 Encoder와 CLIP, VAE 모델이 누락되어 있다는건데...
ComfyUI에서 설정했던 그 파일이 걸리면 될 것 같은데 그렇지 않았고,
설정 또한 비활성화되어서 동작하지 않았습니다.
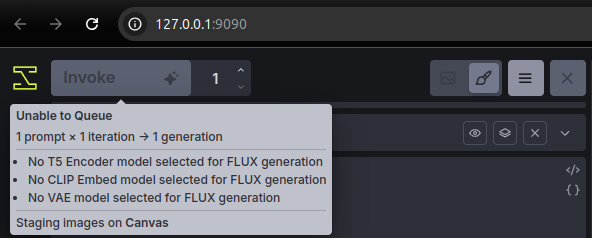
아마도 바로 이전 작업에서 해당 모델들이 제대로 로딩이 되지 않았기 때문일 것 같습니다.
강제로 특정 폴더에 넣고 다시 불러야 하는건지도 모르겠네요.
아무래도 처음에는 권장사항을 따르는 것이 지름길이다 싶어 진행합니다.
Starter Models나 HuggingFace의 repo_id를 이용 방법 중 전자를 선택합니다.
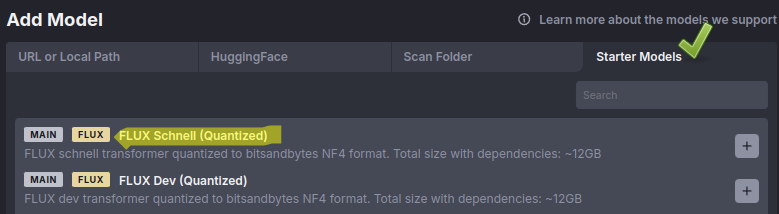
위 방식대로 하면 필요하다고 했던 모델들을 셋트로 자동 설치를 해 줍니다.

여기까지 하고 다시 캔버스로 가보면 비활성화되어 있던 항목들이 꽉 차 있는 것을 볼 수 있습니다. 휴 ~
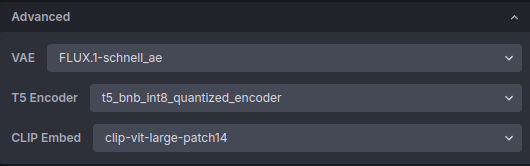
시행착오-3. 생성모델 선택
주의해야 할 것은 위와 같이 등록되었다고 해도 실제 생성할 때 모델을 새로 받은 것으로 지정을 해 줘야 한다는 것입니다.
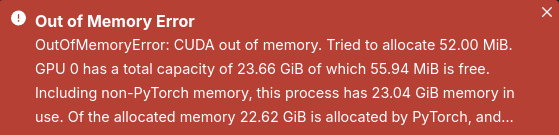
그렇지 않고 기존 ComfyUI에서 사용하던 것이 선택되어 있으면 아래와 같이 VRAM 메모리가 풀 났다고 오류 뜹니다.
분명히 ComfyUI에서는 간당간당하지만 돌아갔던 것인데,
아무래도 변경된 VAE, CLIP, Encoder 등이 메모리를 더 쓰는 모양입니다.
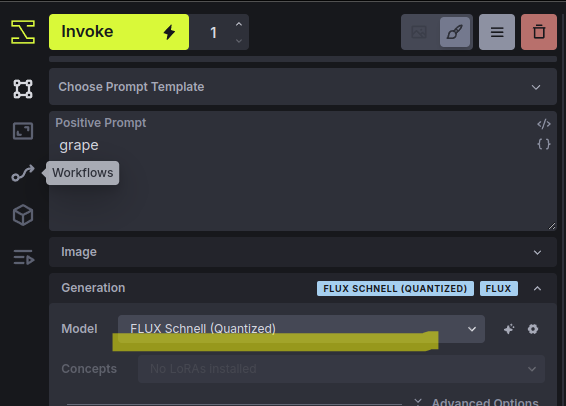
다시 새로 다운받았던 Flux.1 Schnell의 QT버전(NF4)을 선택하고 다시 실행합니다.
nvitop을 이용해 확인해 보면 로딩되는 용량도 더 작고, 로딩 속도고 더 빠른 것 같습니다.
결과 확인
생성된 이미지를 확인해 봅니다.
저는 prompt로 'grape'라는 단어만 사용했습니다.

그럴 듯하게 보이긴 하는데...
원래 서양에서 재배하는 포도는 꼭지 반대편이 이렇게 움푹 들어가나요? 흠...
참고
AI 모델들의 파일 형식 별 간단한 설명을 걸어 봅니다.
이번에 HuggingFace, ComfyUI 등을 하면서 다양한 파일 형식이 나와 헷갈려서 정리해 봤습니다.
AI 모델의 모델 가중치 파일 형식
딥러닝 모델의 가중치 파일은 프레임워크나 용도에 맞춰 최적화되어 있습니다. 주요 가중치 파일의 형식과 특징을 정리해 보고 가겠습니다. HDF5 (.h5, .hdf5)Hierachical Data Format의 약자, 대용량
42morrow.tistory.com
'AI 기술' 카테고리의 다른 글
| Voice-Pro : 음성 관련 통합 서비스를 제공하는 오픈소스 웹 솔루션 (3) | 2024.10.07 |
|---|---|
| gradio-client-lite : typescript도 개발된 경량 gradio client (0) | 2024.10.07 |
| Crawl4AI : 비동기 웹 크롤링 데이터 추출 및 간소화 앱 (0) | 2024.10.07 |
| Flex3D : 고품질의 3D 콘텐츠를 생성하는 모델 (2) | 2024.10.06 |
| LVCD : 스케치 영상을 색칠하는 비디오 확산 모델 (0) | 2024.10.03 |



