

| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- 생성형 AI
- 인공지능
- LLM
- AI
- 오픈소스
- 일론 머스크
- 오픈AI
- 휴머노이드 로봇
- 강화 학습
- OpenAI
- 우분투
- 생성형AI
- tts
- 오블완
- AI 기술
- 메타
- 코딩
- 티스토리챌린지
- 다국어 지원
- 실시간 렌더링
- 확산 모델
- 시간적 일관성
- PYTHON
- 트랜스포머
- 딥러닝
- 3d 재구성
- Stable Diffusion
- OpenCV
- LORA
- ubuntu
- Today
- Total
AI 탐구노트
Crawl4AI : 비동기 웹 크롤링 데이터 추출 및 간소화 앱 본문

얼마 전 Crawling을 전문으로 하는 FireCrawl이라는 솔루션을 소개한 바 있습니다.
Firecrawl : 웹사이트 데이터 크롤링 API 서비스
URL 내용을 크롤링해서 LLM을 위한 마크다운 또는 구조화된 데이터로 변환하는 API 서비스 Firecrawl은 웹 사이트 URL 상의 내용을 크롤링해서 정돈된 마크다운 형태나 LLM에 적합한 구조화된 데이터
42morrow.tistory.com
그랬는데 바로 또 다른 Crawler를 알게 되어 간단한 소개와 실행 테스트를 진행해 봅니다.
Crawl4AI는 비동기 아키텍처를 채용해 웹 데이터를 효율적으로 수집하고 정제하는 자동화된 솔루션으로, 대규모 데이터 크롤링과 고속 처리에 특히 유리합니다.
Crawl4AI의 특징
Crawl4AI의 특징들 가운데 몇 가지 관심을 끈 것은 다음과 같습니다.
- 오픈소스, 무료 (Apache 2.0 라이선스)
- 비동기 아키텍처 (asyncio를 이용)로 매우 빠릅니다!
- 다양한 출력 양식을 지원 (Json, 정리된 HTML, Markdown 등)
- 페이지에서 메타 데이터를 추출합니다.
- 사용자 에이전트를 정의할 수 있습니다.
- 크롤링 전 사용자 정의 Javascript를 실행할 수 있습니다.
- 페이지의 스크린샷 촬영을 지원합니다.
- 추출을 개선하기 위한 지침, 키워드를 전달할 수 있습니다.
설치방법
설치는 pip를 이용해 진행합니다.
해 보니 crawl4ai 설치 시 playwright를 비롯한 필요 패키지가 함께 설치되었습니다.
# crawl4ai 설치
$ pip install crawl4ai
위의 과정 만으로 작업이 끝났다고 생각했었는데 python으로 코드를 생성해서 테스트 하면 오류가 발생합니다.
Playwright 가 필요로 하는 요구 패키지가 설치되지 않아서인데 그 작업을 다음과 같이 실행합니다.
아래 실행을 하면 자동으로 chromium, ffmpeg, firefox, webkit 이 다운받고 설치됩니다.
# playwright 필요 패키지 설치
$ playwright install
사용방법
github에서 제공하는 간단한 코드를 이용해 보겠습니다.
크롤링을 해 볼 곳은 조선일보의 9/30 기사인 '국내 게임사들, AI 접목 올인… "한 달만에 신작 내놨다"' 입니다.
해당 기사는 ChatGPT한테 읽어와 보라고 했을 때 기사로의 직접 접근이 막혀 있었습니다.
이런 경우, 보통 크롤러를 막기 위한 장치가 반영되는 경우가 대부분이죠. (이 사이트도 꼭 그렇단건 아닙니다. 상세 분석은 안 했음)
해당 URL을 읽어와서 표시하는 코드는 다음과 같습니다.
import asyncio
from crawl4ai import AsyncWebCrawler
async def main():
async with AsyncWebCrawler(verbose=True) as crawler:
result = await crawler.arun(url="https://www.chosun.com/economy/tech_it/2024/09/30/O2MFE3VNNVDMDITUNE6ZLCAZ7E/")
print(result.markdown)
if __name__ == "__main__":
asyncio.run(main())
결과 확인
크롤링 결과는 다음과 같습니다.
전체 페이지 크롤링이 되며 아래 박스에 표시한 부분이 해당 기사 부분이 됩니다. (뒷부분은 스크롤 관계로 생략)
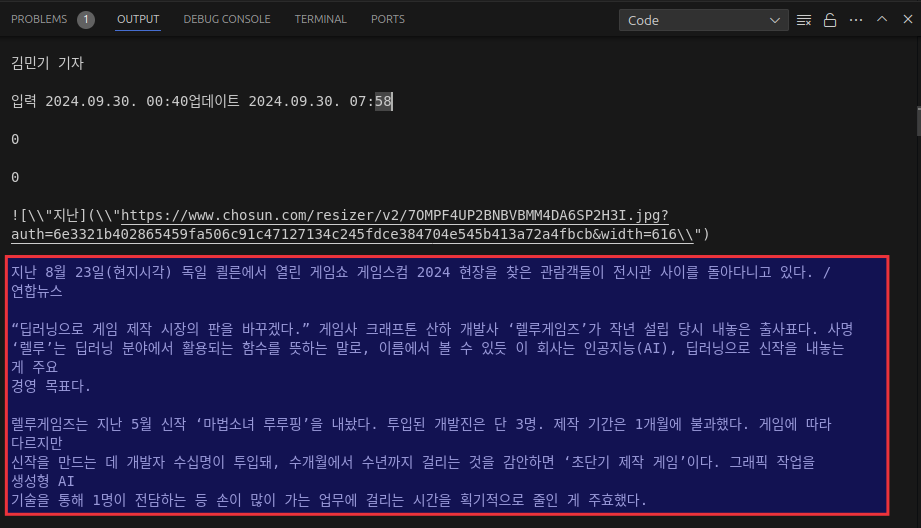
아래 뉴스 사이트의 내용과 비교해보면 아주 훌륭하게 추출한 것을 알 수 있습니다.

확실히 속도는 빠르고 괜찮습니다.
향후 데이터 수집을 위해 필요한 경우에 BeautifulSOAP나 Crawl4AI 등을 활용해서 작업을 해봐야겠습니다.
이번 글은 간단히 새로 나온 크롤러 하나 소개하는 것으로 끝냅니다.
'AI 기술' 카테고리의 다른 글
| gradio-client-lite : typescript도 개발된 경량 gradio client (0) | 2024.10.07 |
|---|---|
| Invoke : 비주얼 미디어를 위한 전문 크리에이티브 AI 도구 (2) | 2024.10.07 |
| Flex3D : 고품질의 3D 콘텐츠를 생성하는 모델 (2) | 2024.10.06 |
| LVCD : 스케치 영상을 색칠하는 비디오 확산 모델 (0) | 2024.10.03 |
| LightLLM : Python 기반 LLM 추론 및 API 제공 프레임워크 (3) | 2024.10.03 |



