

| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- 인공지능
- LLM
- LORA
- 메타
- OpenCV
- AI
- PYTHON
- 확산 모델
- tts
- 오픈AI
- 생성형 AI
- TRANSFORMER
- 일론 머스크
- 티스토리챌린지
- 시간적 일관성
- OpenAI
- 오블완
- 다국어 지원
- 이미지 생성
- 아두이노
- 실시간 렌더링
- 트랜스포머
- AI 기술
- 딥러닝
- 오픈소스
- ChatGPT
- 우분투
- 멀티모달
- 강화 학습
- 휴머노이드 로봇
- Today
- Total
AI 탐구노트
Generative Omnimatte : 동영상 분해를 통한 창의적 편집 기술 본문

1. 서론
동영상 기술의 발전은 단순히 장면을 기록하는 단계를 넘어, 복잡한 시각적 데이터를 분석하고 재구성하는 새로운 차원으로 발전해왔습니다. 그 중에서도 동영상 레이어 분해 기술은 다양한 창의적 활용 가능성을 제시하며 주목받고 있습니다. 예를 들어, 동영상 내 특정 객체를 제거하거나, 그 효과(그림자, 반사 등)를 포함한 객체를 별도의 레이어로 분리하여 영상 제작자들에게 놀라운 자유도를 제공합니다. 그러나 기존 기술은 정적인 배경이나 카메라의 움직임과 같은 제한적인 환경에서만 효과적으로 작동하는 한계를 가지고 있었습니다.
Generative Omnimatte는 이러한 한계를 극복하기 위해 고안된 기술로, 기존의 정적인 가정을 탈피하여 동적인 배경에서도 동작하며, 가려진 영역을 자연스럽게 복원하는 능력을 제공합니다. 이를 위해 사전 학습된 영상 생성 모델을 활용하여 동영상의 각 레이어를 생성하고, 사용자 정의와 같은 복잡한 요구 사항에도 부합할 수 있도록 설계되었습니다. 이 글에서는 Generative Omnimatte의 접근 방식과 기술적인 진보, 그리고 이를 활용한 실질적인 사례를 살펴봅니다.
2. 본론
2.1. 기존 방식의 문제점
기존 Omnimatte 기술은 정적인 배경이나 정확한 깊이 추정 등의 가정을 필요로 하며, 동적인 배경을 처리하거나 가려진 영역을 복원하는 데 한계가 있었습니다. 이러한 가정이 깨질 경우, 객체와 그 효과를 분리하는 데 실패하거나, 결과물이 불완전하게 되는 문제가 발생했습니다.
2.2. 접근 방식
Generative Omnimatte는 사전 학습된 영상 생성 모델을 활용하여 기존 기술의 제약을 극복합니다. 기본적으로 이 접근법은 동영상의 각 프레임을 분석하고, 개별 객체 및 그 효과를 포함하는 레이어를 생성합니다. 특히 동적 배경을 처리하고 가려진 영역을 복원하는 데 강점을 보이며, 이를 위해 "비디오 확산 모델"이라는 최신 기술을 사용합니다.
- 비디오 확산 모델 사용
Generative Omnimatte는 비디오 확산 모델을 사용해 객체와 효과를 학습하고, 이를 분리 및 복원하는 데 활용합니다. 이는 영상 내 시공간적 상관관계를 모델링하여 자연스러운 분해를 가능하게 합니다. - 소규모 데이터로 미세 조정
사전 학습된 모델을 소규모의 실제 및 합성 데이터를 사용해 미세 조정하여, 각 레이어의 정확성과 완성도를 향상시켰습니다.
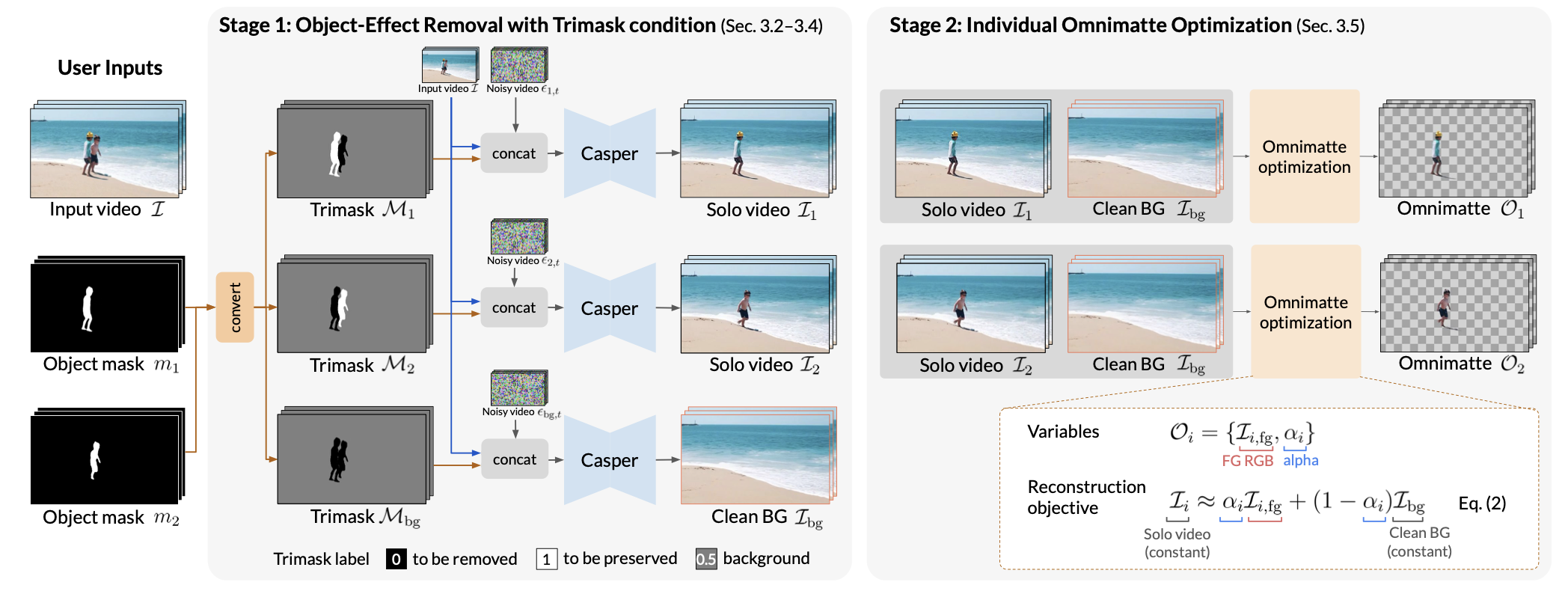
2.3. 세부 적용 기술
- Casper 모델
Casper는 객체와 효과를 제거하는 모델로, 기존 비디오 인페인팅 모델에서 미세 조정을 거쳐 개발되었습니다. 이를 통해 배경 레이어를 깨끗하게 복원하고, 개별 객체가 포함된 "단일 객체 비디오"를 생성합니다. - Trimask 활용
Trimask는 객체와 효과를 더 정확히 구분하기 위해 도입된 기술입니다. 배경, 제거 대상 객체, 보존 영역을 세분화하여 효과적인 분리를 가능하게 합니다. - 효과 연관성 분석
모델의 내부 셀프 어텐션 메커니즘을 활용해 객체와 그 효과 간의 연관성을 파악하며, 이를 통해 그림자나 반사와 같은 효과도 정확히 분리됩니다.
2.4.기술 적용 시 구현할 수 있는 사례 예시
Omnimatte 기술을 활용할 경우, 다음과 같은 다양한 기능 구현이 가능합니다.
- 객체 제거 (Object Removal) : 특정 객체와 그 효과를 완전히 제거하고, 자연스럽게 복원된 배경만을 남길 수 있습니다. (예) 사람이 서 있던 자리를 빈 배경으로 교체
- 레이어 편집 (Layer Editing) : 각 레이어를 개별적으로 편집하여 객체의 속성을 변경할 수 있습니다. (예) 그림자의 방향을 조정하거나, 반사의 강도 줄임
- 시각적 효과 추가 (See-through Foreground) : 반투명 효과를 활용해 전경 객체의 투명도를 조정할 수 있습니다.
- 동작 재조정 (Motion Retiming) : 객체의 움직임을 다시 설정하여 속도를 변경하거나, 특정 장면을 중첩시킬 수 있습니다. (예) 특정 장면을 슬로우 모션으로 변환
- 배경 교체와 크기 조정 (Layer Resizing & Background Replacement) : 객체 크기를 조정하거나 배경을 완전히 다른 이미지로 대체할 수 있습니다.
- ActionShot : 움직이는 객체를 복제하거나, 움직임의 타이밍을 조정해 새로운 시각적 연출을 만듭니다. (예) 달리는 사람을 복제해 동시다발적으로 달리는 장면 생성
2.5. 기술의 특징, 장점
기존 기술 대비 Generative Omnimatte가 가진 가장 큰 장점은 다음과 같습니다.
- 가려진 영역 복원: 객체에 의해 가려진 배경이나 다른 객체를 자연스럽게 복원합니다.
- 정확한 효과 연관성 : 객체와 그 그림자, 반사 등의 효과가 정확히 분리, 연결 됩니다.
- 동적 배경 지원: 배경이 움직이는 장면에서도 높은 품질의 분해 및 편집을 지원합니다.
2.6. 제약사항
본 기술은 사전 학습된 데이터의 범위와 품질에 따라 성능이 좌우될 수 있으며, 복잡한 물리적 변형(예: 변형된 물체의 그림자)과 같은 특정 효과에 대한 처리가 제한적일 수 있습니다.
3. 결론
Generative Omnimatte는 동영상 레이어 분해 기술의 한계를 넘어 새로운 차원의 편집 가능성을 제공합니다. 동적 배경에서도 자연스러운 분리와 복원이 가능하며, 창의적 영상 제작의 도구로 활용될 수 있습니다. 향후 더 풍부한 데이터와 학습 기법이 도입된다면, 물리적 변형까지 포괄하는 기술로 발전할 가능성이 큽니다. 이는 영상 편집, 영화 제작, 가상현실 콘텐츠 생성 등 다양한 분야에서 활용될 것으로 기대됩니다.
4. 참고자료
Generative Omnimatte: Learning to Decompose Video into Layers
We use different trimask conditions for an input video to obtain a set of single-object (solo) videos and a clean-plate background video (bottom row). Note that we do not cherry pick the random seeds for the Casper model. We use the same random seed (=0) f
gen-omnimatte.github.io
5. Q&A
Q.Generative Omnimatte는 어떤 문제를 해결했나요?
기존 Omnimatte 기술의 정적 배경 가정 및 제한된 복원 능력을 극복하여, 동적 배경에서도 객체와 효과를 분리하고 가려진 영역을 자연스럽게 복원합니다.
Q.Trimask의 역할은 무엇인가요?
Trimask는 객체와 효과를 세밀히 구분하여, 보존 영역과 제거 영역을 명확히 정의해 정확한 레이어 분리를 가능하게 합니다.
Q.어떤 응용 사례가 있나요?
동영상 내 객체 제거, 배경 교체, 그림자 및 반사의 분리와 같은 편집 작업이 가능하며, 창의적 영상 제작에 활용됩니다.
'AI 기술' 카테고리의 다른 글
| MCP (Model Context Protocol) : AI시스템과 데이터 소스 연결 기술 (2) | 2024.11.29 |
|---|---|
| AI Video Composer : 쉽고 빠른 영상 제작 도구 (3) | 2024.11.28 |
| The Matrix : 사실적 세계 시뮬레이션을 위한 실시간, 프레임 레벨 컨트롤 (0) | 2024.11.24 |
| SAMURAI : 동적 환경에서의 객체 추적 (0) | 2024.11.23 |
| AI 기반 디지털 사이니지: 광고 효과 측정의 새로운 시대 (3) | 2024.11.21 |



