

| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- 딥러닝
- 인공지능
- 트랜스포머
- tts
- 생성형AI
- LLM
- OpenAI
- 오픈소스
- 우분투
- 실시간 렌더링
- 멀티모달
- OpenCV
- 강화 학습
- 메타
- LORA
- 휴머노이드 로봇
- PYTHON
- 시간적 일관성
- 자연어 처리
- 일론 머스크
- ai 챗봇
- gaussian splatting
- 강화학습
- AI
- 오블완
- ChatGPT
- 오픈AI
- 확산 모델
- 티스토리챌린지
- AI 기술
- Today
- Total
AI 탐구노트
DiffRhythm : 빠르고 일관성있는 혁신적인 음악 제작 기술 본문

음악 생성 기술은 최근 몇 년간 급격한 발전을 이루었으며, 인공지능(AI) 기반의 음악 생성 모델들은 새로운 창작 방식의 가능성을 열어가고 있습니다. 기존의 음악 생성 시스템은 보컬과 반주 트랙을 개별적으로 생성하거나, 다단계의 복잡한 아키텍처를 거쳐야만 고품질의 음악을 만들 수 있었으나 이러한 방식은 확장성이 부족하고, 짧은 음악 조각만을 생성하는 경우가 많아 실질적인 음악 창작 도구로 사용하기에는 한계가 존재했죠.
특히, 최근까지 대부분의 음악 생성 모델들은 자연어 처리에서 사용되는 언어 모델(Language Model) 기반의 접근 방식을 차용해 왔습니다. 하지만 이러한 모델들은 연산 비용이 높고, 추론 속도가 느려 실시간 응용에는 적합하지 않았고 이에 따라 빠르고 간결하면서도 고품질의 곡을 생성할 수 있는 새로운 방식의 필요성이 제기되었습니다.
DiffRhythm은 이러한 문제를 해결하기 위해 설계된 최초의 잠재 확산(latent diffusion) 기반 곡 생성 모델입니다. 이 모델은 가사와 스타일 프롬프트만으로 최대 4분 45초 길이의 곡을 단 10초 만에 생성할 수 있으며, 기존 모델들에 비해 훨씬 간단한 구조를 가지며 비자기회귀(non-autoregressive) 방식을 채택하여 빠른 추론 속도를 유지하면서도 음악적 일관성과 보컬의 명확성을 보장합니다.
기존 음악 생성 모델의 제약 사항
기존 방식들은 주로 다음과 같은 문제점을 가지고 있었습니다.
- 보컬과 반주의 개별 생성 (Aka. '따로 놀기') : 보컬과 반주를 별도로 생성하다 보니 두 요소 간의 자연스러운 결합이 어려웠습니다.
- 다단계 처리로 인한 복잡성 : 여러 단계에 걸친 모델과 정교한 데이터 전처리 과정이 필요해, 확장성과 구현이 복잡했습니다.
- 느린 추론 속도 : 대부분의 언어 모델 기반 방식은 생성 과정이 순차적으로 이루어져 실시간 응용에 부적합할 정도로 추론 속도가 느렸습니다. 주로 짧은 음악 클립(예: 30초~1분)을 생성하는 데 집중되어 있었죠.
- 짧은 음악 조각만 생성 : 전체 노래가 아닌 짧은 음악 구간만 생성할 수 있어, 실질적인 음악 제작에 한계가 있었습니다.
DiffRhythm
1) 기술 소개 및 접근 방식
DiffRhythm은 기존 모델들의 한계를 극복하기 위해 잠재 확산 모델(latent diffusion model, LDM)을 기반으로 설계되었습니다. 주요 특징은 다음과 같습니다.
- 엔드 투 엔드 곡 생성 : 보컬과 반주를 동시에 생성하여 자연스럽고 일관된 음악을 생성
- 문장 단위 가사 정렬(sentence-level lyrics alignment) : 가사와 보컬의 싱크를 보다 정확하게 맞추는 새로운 정렬 기법을 적용
- 비자기회귀(non-autoregressive) 방식 : 반복적인 토큰 예측이 아닌 병렬 연산을 통해 빠른 곡 생성 속도 달성
- VAE 기반 잠재 공간 활용 : 오디오 데이터를 저차원의 잠재 공간(latent space)에서 처리하여 연산량 절감, 효율성 향상
2) DiffRhythm의 핵심 기술

위 그림은 스타일 정보와 가사를 외부 제어 신호로 사용하여, 디퓨전 트랜스포머(DiT)가 잠재 공간에서 노이즈 제거를 수행한 후 VAE 디코더를 통해 최종 오디오를 생성하는 전체 흐름을 보여줍니다.
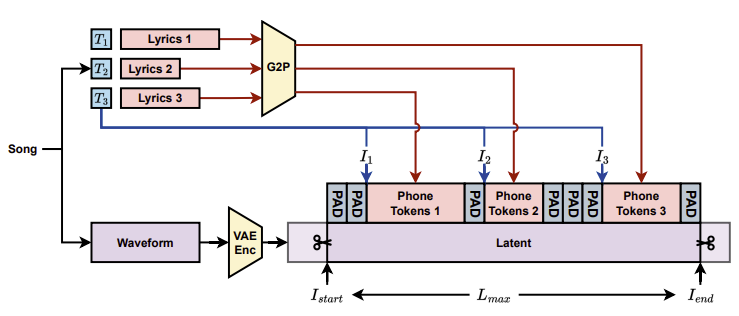
위의 그림은 가사가 어떻게 Grapheme-to-Phoneme(G2P) 변환을 거쳐 오디오 신호의 특정 위치 (잠재표현)에 대응되도록 처리하는 과정을 보여주고 있습니다.
3) 주요 세부 기술
- Latent Diffusion (잠재확산)
오디오 데이터를 낮은 차원으로 압축한 후, 노이즈 제거 과정을 통해 고품질 음원을 생성합니다.
원본 음원을 다루는 것은 계산량이 많고 복잡하기 때문에 압축된 형태(Latent Space)로 변환 후 그 공간에서 음악을 생성함. 사진을 흐릿하게 만든 후 점차 선명하게 복원하는 것과 유사함
- VAE (Variational Autoencoder) - 음악 데이터 압축 및 복원
원본 음원을 잠재 공간으로 인코딩하고, 이를 복원하는 과정을 통해 음원의 중요한 특징을 보존하며 계산 효율성을 높입니다. - Diffusion Transformer (DiT)
트랜스포머 기반 모델로, 잠재 공간에서 반복적인 디노이징 과정을 통해 노래를 생성합니다.
이 과정은 기존의 언어 모델 기반 방식보다 빠르고 효율적입니다. 머릿 속 멜로디를 점점 선명하게 만들어가는 과정에 비유될 수 있습니다. LLaMA 최적화 라이브러리(Unsloth, Liger-Kernel)와 FlashAttention2를 적용하여 학습 및 추론 속도를 25% 이상 개선했는데 이는 기존의 자기회귀방식 대비 50배 빠른 속도라고 합니다.
- 문장 단위 가사 정렬 (Lyrics-to-Latent Alignment) - 가사와 노래를 맞추는 기술
가사의 각 문장을 음성 신호의 특정 구간에 정렬하여, 보컬과 가사 간의 자연스러운 일치를 보장합니다. 노래방 기기에서 가사가 노래 리듬에 맞춰 흐르듯 표시되는 것을 생각하시면 될 것 같습니다. - 비자동회귀 구조 (Non-Autoregressive Architecture) - 빠른 생성 속도
기존 한 음씩 순차적으로 생성하는 방식 대신 하번에 전체적인 음악을 만들어 내며 결과적으로 전체 노래 생성에 있어 일관성도 높입니다.
4) 생성 테스트
HuggingFace에 테스트 해 볼 수 있는 데모가 공개되어 있습니다. 임의의 내용으로 해 보면 제대로 나올까 싶은 호기심에 간단한 것 하나를 해 봤습니다.
가사 선정
정호승 님의 시 가운데 '슬픔이 기쁨에게'라는 것이 있는데 내용의 일부를 파파고 번역기를 돌려서(시인께는 죄송합니다! ^^;) 영문으로 만든 후 그것을 가지고 노래를 만들어 달라고 해 봤습니다. 감정선을 건드리는 형태로 나오는지를 한번 확인해 보기 위해서였는데 결과는 의외로 좋았습니다.
입력 데이터 생성
입력 텍스트는 '[시작 시간] 가사' 형태로 생성되어야 합니다. 저는 음악에 소질은 없는지라... 대충 이 정도 간격이면 되겠지 싶은 수치로 시의 각 줄이 시작되는 시간을 설정했습니다.

결과 확인
생성된 곡에서 맨 마지막 줄은 한참 뒤에 생성되어 있어서 5번째 줄까지 생성된 것만으로 크롭했습니다. 노래 가사는 전주를 거쳐 10초부터 나옵니다.
DiffRhythm은 복잡한 데이터 전처리 없이도 전체 노래를 빠르고 효율적으로 생성할 수 있는 혁신적인 기술입니다. 단순하면서도 강력한 모델 구조와 문장 단위 가사 정렬 메커니즘을 통해, 음악 제작의 새로운 가능성을 열어가고 있습니다. 이처럼 첨단 딥러닝 기법을 활용한 DiffRhythm은 향후 상업적 음악 제작뿐만 아니라, 창작 활동에도 큰 도움을 줄 것으로 기대됩니다.
참고자료
- 논문) DiffRhythm: Blazingly Fast and Embarrassingly Simple End-to-End Full-Length Song Generation with Latent Diffusion (링크)
- 코드) DiffRhythm 깃헙 (링크)
- 데모) HuggingFace Space (링크)
Q&A
Q. DiffRhythm이 기존 음악 생성 모델보다 빠른 이유는?
자기회귀 방식이 아닌 비자기회귀적(non-autoregressive) 접근법을 사용하여 병렬 연산이 가능하기 때문입니다.
Q. DiffRhythm은 어떤 데이터를 사용하여 학습되었나?
100만 개 이상의 곡(약 60,000시간 분량)을 사용하여 학습되었으며, 다국어 지원(중국어 30%, 영어 60%, 기악 10%)이 가능합니다.
Q. 음악의 스타일을 조절할 수 있는가?
현재는 스타일 레퍼런스 오디오를 제공해야 하지만, 향후 텍스트 기반 스타일 컨트롤 기능이 추가될 예정입니다.
'AI 기술' 카테고리의 다른 글
| GLM(Grounded Language Model) : 정확성 높은 RAG 2.0 기반 언어모델 (1) | 2025.03.09 |
|---|---|
| Phi-4 : Mixture-of-LoRAs를 활용한 강력한 멀티모달 언어 모델 (0) | 2025.03.08 |
| NotaGen : 클래식 음악을 작곡하는 심볼릭 음악 생성 모델 (0) | 2025.03.05 |
| olmOCR: PDF에서 자연어 처리를 위한 최적의 텍스트 추출 솔루션 (0) | 2025.03.04 |
| Wan 2.1 : 알리바바 그룹의 고품질 영상 생성 모델 (1) | 2025.03.04 |



