

| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- 티스토리챌린지
- 우분투
- ChatGPT
- 오블완
- LORA
- 인공지능
- 아두이노
- 트랜스포머
- 멀티모달
- 딥마인드
- 생성형 AI
- AI
- LLM
- 확산 모델
- 휴머노이드 로봇
- AI 기술
- 딥러닝
- OpenAI
- 뉴럴링크
- 가상환경
- PYTHON
- ControlNet
- 오픈AI
- 메타
- 시간적 일관성
- ubuntu
- TRANSFORMER
- 서보모터
- tts
- 일론 머스크
- Today
- Total
AI 탐구노트
흡연 감지 : 다같이 사는 세상, AI로 유도하는 작은 배려 본문

흡연의 문제점, 이제는 전 세계적인 추세
어린이집, 공공 실내 공간, 공원 등 금연구역으로 지정된 곳에서 흡연은 여전히 문제가 되고 있습니다. 특히 어린이나 취약계층이 주로 이용하는 공간에서의 흡연은 큰 문제가 되고 있습니다. 실제로는 먹고 자고 하는 주택, 아파트 단지 등에서도 늘상 겪게 되는 것이 흡연과 관련된 갈등이죠.
해외의 경우, 최근 흡연과 관련해서는 영국과 이탈리아 밀라노의 전향적인 정책이 눈에 띕니다. 작년 4월에 영국에서는 2009년 생 이후 세대는 평생 담배를 살 수 없도록 하는 법안('담배와 전자담배법안')이 법안 심사의 첫 단계를 통과 되었습니다. (기사) 이 법안은 추가적으로 학교, 병원, 놀이터 등 특정 실외 공간같은 곳에서의 흡연도 금지하며 전자담배광고, 스폰서도 금지됩니다. 여기에 더 나아가서 식당이나 술집, 실내 뿐만 아니라 야외 자리에서도 흡연을 금지하는 방안을 추진 중이라는 보도도 있었습니다. (기사)
이탈리아 밀라노에서는 다른 사람들과 10m 이상 떨어진 고립된 공간을 제외한 모든 실외 장소에서 흡연을 할 수 없고 어기면 40~240유로까지의 벌금이 부과하는 금연 정책 시행을 발표했습니다.
공공장소 금연, 기술의 손길이 닿다
금연 구역에서 흡연하는 것을 사람의 눈에 의존해서 감시하는 방식에는 비용, 인력 측면에서 한계가 있습니다. 영상분석 기반의 AI 기술은 이러한 문제를 효과적으로 보완할 수 있는 대안으로 주목받고 있습니다. 국내 지자체 중 일부는 어린이집 근처에 AI 키오스크를 두고 주변에서 흡연하는 사람이 있으면 경고를 보내는 시범 서비스를 시작한 곳도 있습니다.
AI 기반의 흡연자 감지 시스템은 카메라와 센서를 통해 공공장소를 모니터링하며, 담배 연기와 불꽃 등을 실시간으로 탐지합니다. 이를 통해 즉각적인 경고 메시지를 보내거나, 관리자가 문제를 해결할 수 있도록 알리는 방식으로 작동합니다. 이런 금연구역에서 흡연을 감지하는 AI 시스템은 단순히 기술적 편의를 넘어, 공공의 배려와 안전을 실현하는 중요한 역할을 할 수 있습니다. 흡연자에게는 빅브라더와 같은 껄끄러운 존재일 수도 있겠고 담배 연기를 싫어하는 사람들에게는 꼭 있었으면 하는 존재가 되는 양면성을 가지면서 말이죠.
이번 글에서는 영상 분석 기반으로 담배를 피우고 있는 사람 (=흡연자)를 감지하는 기술을 소개하고 테스트 해 보겠습니다.
인공지능이 흡연자를 판별하는 방식
- 객체 검출 (Object Detection)
AI 모델은 영상 내에서 담배, 라이터, 필터 등 흡연과 관련된 물체를 인식할 수 있습니다. 이를 위해 딥러닝 기반의 객체 검출 알고리즘(예: YOLO, Faster R-CNN)을 사용하여 프레임 내에서 특정 물체를 식별합니다. 담배의 형태, 색상, 크기 등을 학습하여 정확하게 검출할 수 있습니다. - 행동 인식 (Action Recognition)
흡연은 단순히 물체를 소지하는 것뿐만 아니라 특정한 행동 패턴을 포함합니다. 예를 들어, 담배를 입에 대고 피우는 동작, 불을 붙이는 동작 등이 있습니다. 3D Convolutional Neural Networks (3D CNNs) 또는 Long Short-Term Memory (LSTM) 같은 시퀀스 모델을 활용하여 시간에 따른 행동 패턴을 분석하고 흡연 동작을 인식합니다. - 비디오 시퀀스 분석 (Temporal Analysis)
단일 프레임보다는 연속된 프레임에서의 변화를 분석하는 것이 중요합니다. 시간적 정보를 활용하여 흡연자의 동작을 보다 정확하게 파악할 수 있습니다. 예를 들어, 손의 움직임, 입과 담배의 상호작용 등을 시간 축을 따라 분석합니다. - 컨텍스트 인식 (Contextual Cues)
흡연은 특정한 장소나 상황에서 이루어지는 경우가 많습니다. 예를 들어, 실내에서는 흡연이 금지된 경우가 많기 때문에, 실외에서의 흡연 동작을 더욱 주의 깊게 분석할 수 있습니다. 장소 인식 및 환경 분석을 통해 더 높은 정확도를 달성할 수 있습니다. - 멀티모달 데이터 통합 (Multimodal Data Integration)
영상뿐만 아니라 오디오 데이터를 함께 분석하면 더욱 정확한 판별이 가능합니다. 예를 들어, 담배 피우는 소리나 불을 피우는 소리를 감지하여 흡연 여부를 보완적으로 판단할 수 있습니다.
판별 시 어려움과 모델 개발 시 고려사항
영상 분석을 통해 흡연자를 판별할 때 AI가 직면할 수 있는 어려움에는 다음과 같은 것이 있습니다. 사실 AI가 아니라 사람이라도 비슷한 어려움을 겪게 될 것 같긴 합니다. 이런 점을 고려해서 AI 모델 설계, 데이터 수집, 학습 등을 진행해야 합니다.
- 환경적 요인 : 조명 변화 (실내/실외, 낮/밤 등), 기상 조건(비,눈,안개 등), 배경의 복잡성/변동성 등을 고려한 강인한 모델이 필요합니다. 예를 들어 조명의 변화나 배경이 복잡하거나 변화무쌍하면 감지하려는 객체와 구분이 잘 안 될 수 있습니다.
- 개인차 : 사람 별로 흡연 동작의 패턴이나 사용하는 도구 (예: 전자담배, 파이프, 시가 등)가 다양하므로, 이를 포괄적으로 학습시켜야 합니다. 객체와 행동의 모호성이 존재하기 때문인데, 예로 흡연자세와 유사한 동작을 하거나 혹은 감지하려는 연기가 제대로 인식되지 않을 수 있습니다.
- 영상의 품질 이슈 : 사용하는 CCTV, 카메라 등에 따라 영상 품질, 해상도 등이 기준에 못 미칠 수 있습니다. (예: 저해상도의 구형 CCTV 사용 등)
- 프라이버시 : 개인의 사생활을 침해하지 않도록 데이터 수집 및 사용에 신중을 기해야 합니다.
흡연 감지 테스트
이번 글에서 사용할 공개 기술은 Cigareete Smoking Detection (Github 링크) 입니다. 해당 Github repository에서는 이 모델을 다음과 같이 표현하고 있습니다.
YOLOv8-Pose + BYTETRACK + RTDETR Cigarette Detection + Openvino/Onnxruntime/TensorRT Deployment
즉, 자세 예측, 트래킹, 감지 기술을 함께 사용하고 추론 최적화를 위한 추가 모듈을 사용했다는 것입니다.
환경 구성 및 필요 패키지 설치
가상 환경을 하나 생성하고 진행합니다. conda 혹은 venv 둘 다 무관합니다.
# 가상환경 생성
$ conda create -n cgr python==3.12
사용할 모델을 다운로드 합니다.
# 코드 다운로드
$ git clone https://github.com/Leviathanlzx/cgr_detection
$ cd cgr_detection
필요한 패키지를 설치합니다. 이후에 프로그램 실행 시 이 파일에 명시되어 있지 않은 패키지가 일부 필요할 수 있습니다. 이는 실행 시 로그를 확인해서 하나씩 하면 됩니다.
$ pip install -r requirements.txt
사전학습 모델 weight 준비
기본 제공되는 weight 파일은 last.onnx, yolov8n-pose.onnx 두 개이며 각각 담배 감지, 자세 감지 모델로 판단됩니다. 판단된다고 한 것은 last.onnx 파일에 대해 상세 설명이 없기 때문인데 딱 봐도 그럴 것 같아서, github repo 상의 코드에서는 yolov8-cgr.onnx 파일을 찾고 있길래 last.onnx 파일의 이름을 변경해주고 진행했습니다.
첨부된 코드들을 보면 TensorRT, Openvino, Onnx 등 다양한 타입을 이용할 수 있도록 되어 있습니다. 즉, 기본 제공되는 weight 파일을 이용해서 나머지 파일은 직접 생성해야 한다는 얘기입니다. 하지만, 제 경우는 그렇게까지 할 것은 아니라 기본 제공되는 onnx 타입만 이용해서 돌려보는 것에 만족합니다.
테스트 진행
주의) Github Repository에는 models 폴더로 되어 있는데, 실행 코드들에는 model 폴더로 되어 있는 오류들이 보입니다. 이는 작업 전에 일괄 수정해 줘야 이상이 없을 겁니다.
1) qt_main.py 를 이용한 GUI 방식
QT를 이용해서 GUI로 사용하는 것은 편리하긴 합니다. 하지만, 제 Ubuntu 쪽 환경 설정에서 conda와 pip 간의 중복 설치, 버전 충돌 등으로 인해 문제 해결을 하는데 많은 시간이 소요되었습니다. 다양한 테스트를 하려다보니 이것저것 꼬인 것이 많았는데 행여라도 저같은 시행착오는 하지 마시길 빕니다.
$ python qt_main.py
실행 결과는 다음과 같습니다. 한자로 되어 있는 부분들은 구글 렌즈나 혹은 구글 번역기를 이용하면 어떤 내용인지 보실 수 있습니다. 참고로 여기서는 keypoint와 담배감지 bbox 출력은 하지않도록 설정되어 있습니다.
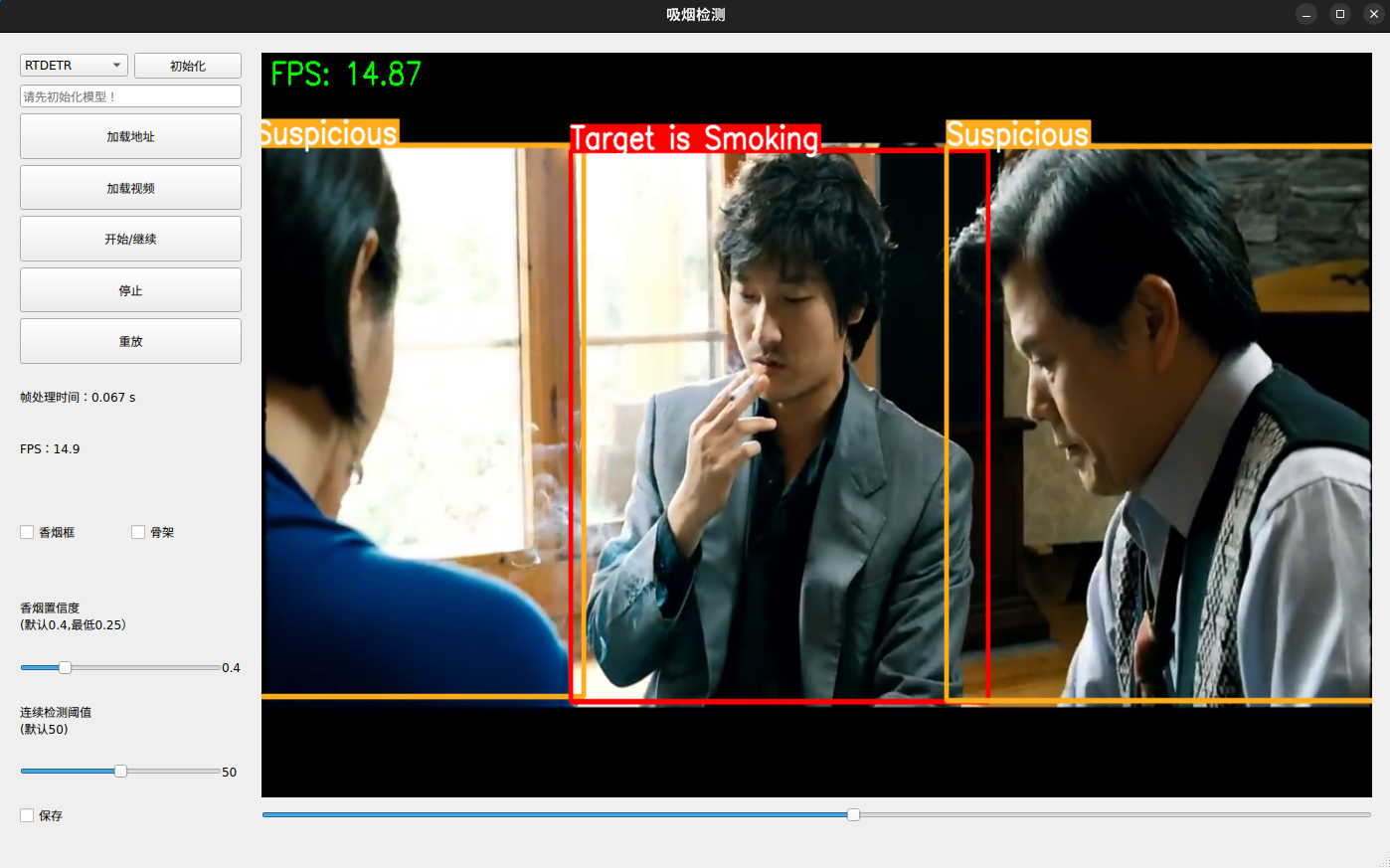
2) infer_main.py 이용한 방식
OpenCV를 이용해 화면에 바로 표시하는 방식입니다. 원본에 있는 코드에서 CLI 인자로 받는 부분을 직접 설정하는 방식으로 하고 표시하게 되는 내용만 일부 수정했습니다.
import cv2
import time
from ov_inference import pose_estimate_with_onnx
from func import detect_and_draw
class Result:
def __init__(self,box,score,id,kpts):
self.xyxy=box
self.conf=score
self.id=id
self.keypoints=kpts
if __name__ == '__main__':
from types import SimpleNamespace
opt = SimpleNamespace(cgr_conf=0.4, skeleton=True, cig_box=True, threshold=50)
# capture stream using youtube video url
from cap_from_youtube import cap_from_youtube
from datetime import timedelta
youtube_url = 'https://www.youtube.com/watch?v=BnYyX8_c4I8&t=71s'
start_time = timedelta(seconds=5)
cap = cap_from_youtube(youtube_url, 'best', start=start_time)
cv2.namedWindow("Multi Person Pose Detection", cv2.WINDOW_NORMAL)
cv2.resizeWindow("Multi Person Pose Detection", 1280, 720)
while cap.isOpened():
start_time = time.time()
ret,image=cap.read()
if not ret:
break
box, score, ids, kpts=pose_estimate_with_onnx(image)
if ids and box is not None:
pose_result=[Result(i,j,k,m) for i,j,k,m in zip(box, score, ids, kpts)]
image = detect_and_draw(pose_result, image,opt)
current_time = time.time()
elapsed_time = current_time - start_time
fps = 1 / elapsed_time
cv2.putText(image, f"FPS: {round(fps, 2)}", (10, 30), cv2.FONT_HERSHEY_SIMPLEX, 1, (0, 255, 0), 2)
cv2.imshow("Multi Person Pose Detection", image)
key = cv2.waitKey(1)
if key == ord('q'):
break
cap.release()
cv2.destroyAllWindows()
테스트 결과는 다음과 같습니다. 원본 코드(infer_main.py)에서 keypoint와 담배 bbox 표시하는 부분을 기본값에서는 표시하지 않도록 되어 있는데 True로 변경했습니다.

위의 이미지만 보면 테스트 결과는 괜찮아 보입니다. 하지만, 사실은 체리피키이죠. 개인적인 생각으로는 이 정도 수준이라도 충분히 활용 가능하다고 생각되지만 개별 프레임 별로 따져보면 튜닝이나 추가적인 학습이 필요하다는 생각이 들 수도 있겠다 싶습니다. 일단은 가능성을 확인한 것에서 높은 점수를 주고 싶습니다.
마무리하며...
지금까지 흡연자를 감지하는 모델을 테스트해 봤습니다. AI 기술을 이용해 흡연자를 파악하는 것은, 어린이가 있는 곳이나 공공연하게 다수가 피해를 볼 수 있는 그런 장소 (예: 금연구역 등)에서의 갈등을 사전에 막기 위한 목적도 있습니다. 뿐만 아니라 폭발 위험이 있는 물품을 다루는 곳에서는 사고 예방용으로도 활용할 수 있겠죠.
일반적으로 아파트 단지 내에서도 흡연으로 인한 주민들간의 갈등이 자주 발생합니다. 제가 사는 곳만해도 하루에도 몇 차례씩 흡연 자제 당부가 스피커로 전해지기도 하죠. 밤이나 낮이나 가릴 것 없이 말입니다. 참 신기한게... 1층 주차장 쪽에서 피는 담배냄새는 아파트 고층에 있는 배란다에서도 냄새가 납니다. 빨래에 냄새가 배이지 않을까 걱정할 정도로요.
반대로 흡연하시는 분 입장에서는, 아파트 내부건 외부 공간이건 흡연을 마음놓고 할 수 있는 공간이 없다는 항변을 하실 수도 있을 것 같습니다. 그렇다고 아파트 바깥으로 나가서 피울 공간을 쉽게 찾을 수 있는 것도 아니고... 제 경우는 흡연을 하지 않습니다. 담배 냄새를 맡으면 머리도 어지럽고 눈도 따갑죠. 하지만, 회사 생활에서 간접 흡연에 자주 노출되다보니 크게 신경을 쓰지는 않습니다. 흡연자들의 입장도 이해될 때도 있구요.
사실 이런 갈등은 상대방에 대한 '배려'를 조금씩만 더 해 주면 많이 없어질 것 같습니다. 흡연자와 비흡연자 모두가 서로를 이해하고 배려하는 마음을 갖춰야 한다는 얘기죠. 금연구역에서의 흡연 문제를 AI 기술로 해결하려는 노력은 단순히 편리함을 넘어, 공공의 이익과 개인의 권리가 조화를 이루는 길을 찾는 과정이라고 볼 수 있습니다. 한발짝씩 다들 양보하는 노력이 필요하다는 얘기죠.
그리고, AI를 적용하려는 쪽에서도 대상이 되는 사람들에 대한 공감과 배려가 기본이 되도록 할 필요가 있습니다. 흡연이라는 것이 사회적으로는 부정적인 인상을 줄 수 있기 때문에, 영상의 수집과 학습 시에 프라이버시가 보호되도록 조치를 취해야 하고, 감지가 되었다고 하더라도 이들에 대한 유연한 가이드가 될 수 있도록 하는 조치도 필요할 겁니다. 기술이 단지 문제 해결의 수단을 넘어, 서로를 위한 작은 배려로 이어질 수 있다는 가능성을 보여줄 수 있다면 좋겠다는 생각 때문에 한번 언급해 봤습니다.
참고자료
- 데이터셋) Cigarette_smoker_detection 데이터셋 (링크)
- 흡연/비흡연 이미지 (각 1996/1279장) 포함
- 데이터셋) CigDet (Cigarette Detection) Dataset (링크)

- 데이터셋) Smoking Detection을 위한 데이터셋 (링크)
- 논문) Intelligent Recognition of Smoking and Calling Behaviors for Safety Surveillance (링크)

- 논문) Using Computer Vision to Detect E-cigarette Content in TikTok Videos (링크)
틱톡 영상 콘텐츠에서 전자담배를 감지하는 모델

- 블로그) Balefire: Navigating the Challenges of Edge AI in Smoking Detection (미디엄, 2024.3)
싱가폴 스타트업 GovTech의 Balefire라는 솔루션 관련 소개 - 영상) 싱가폴의 AI 스타트업인 Dilu Technologies 사의 솔루션 (유튜브)
벌금 천국이라 불리는 싱가폴에서 이런 솔루션이 어떤 용도로 사용될 수 있을지 우와... 겁나네요.

- 영상) Mediapipe와 감지 기술을 이용한 사례 (Tiktok)
Mediapipe와 OpenCV 기술을 결합해서 판별하고 있음


- 코드) Realtime-Smoking-Detection (Github, 대구 OpenBank 프로젝트, 2021.8)
기본적으로는 센서와 영상 분석을 함께 진행하고 있음. 영상 분석에서 자세 예측 기술을 접목함

'DIY 테스트' 카테고리의 다른 글
| AI를 이용한 간단한 안면 식별 서비스 개발 테스트 (1) | 2025.01.07 |
|---|---|
| SAHI 의 적용 : 작은 물체 감지 테스트 (1) | 2025.01.05 |
| 인공지능 영상 분석으로 화재를 감지하는 기술 (9) | 2025.01.02 |
| 마법같은 숫자의 조합 - 마방진(魔方陣) (2) | 2024.12.31 |
| AI를 이용한 도난 감지 : 무인화 매장 확산을 위한 필요 요소 (3) | 2024.12.28 |



