

| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- PYTHON
- 아두이노
- OpenCV
- 강화 학습
- 인공지능
- 생성형 AI
- 일론 머스크
- 확산 모델
- 티스토리챌린지
- 딥러닝
- AI 기술
- ChatGPT
- 오블완
- 휴머노이드 로봇
- LORA
- TRANSFORMER
- 메타
- 트랜스포머
- LLM
- 실시간 렌더링
- 시간적 일관성
- tts
- 이미지 생성
- OpenAI
- 오픈AI
- 다국어 지원
- AI
- 멀티모달
- 우분투
- 오픈소스
- Today
- Total
AI 탐구노트
차량 번호판 인식 본문

1. 개요
자동차 번호판 감지는 다양한 방식으로 구현될 수 있습니다.
- 영상 기반의 전통적 이미지 처리 방식 : 번호판의 윤곽선을 감지하고 사각형 형태의 번호판 영역 찾기를 하는 방식
- 딥러닝 기반 객체 탐지 모델 방식 : 자동차 번호판을 객체로 학습하여 이를 감지하는 방식, 차량을 먼저 찾고 거기서 다시 번호판을 찾는 방식 또는 바로 번호판을 찾는 방식으로 나뉠 수도 있음
- 하이브리드 방식 : 이미지 처리 기술로 번호판 가능성 있는 영역을 먼저 찾고 딥러닝으로 정확한 위치를 파악하는 방식
예전에는 OpenCV의 비전 기술을 이용해서 번호판 윤곽을 추출해서 찾는 첫번째 방법을 많이 사용했습니다. 현재도 많은 곳에서는 이렇게 처리하고 있을테구요. 하지만, 감지하려는 객체의 크기가 어느 정도가 되어야 하고 다양한 엣지케이스에서는 제대로 된 성능을 내지 못한다는 문제가 있어서 특정한 요건에 맞는 지역 (예: 주차장 출입구 한정) 등에 적용된 사례가 많습니다. 그러다가, 딥러닝 모델을 통해 다양한 객체의 감지가 가능해지면서, 번호판 감지 또한 이를 활용하게 바뀌어 가고 있습니다. 감지 모델의 경우, 처리 속도 때문에 대부분 Yolo 나 자체 경량화를 한 전용 모델을 만들어 사용하는 경우가 많죠.
이번 글에서는 객체감지 모델인 Yolo 시리즈와 OCR 모델인 PaddleOCR를 이용해서 자동차 번호판을 인식하고 여기서 번호를 추출하는 것을 한번 해 보겠습니다. 러프하게 해서 동작하는 것만 확인하는 것을 목표로 하겠습니다. 실제 상용으로 서비스하려면 단순한 기능 외에 많은 고려사항들과 영상 품질에 대한 전처리, 후처리 등등 해야할 것이 엄청 많기 때문입니다.
Yolo 자체는 객체 감지 모델입니다. 그렇기 때문에 자동차 번호판을 감지할 수 있도록 별도의 데이터셋을 이용해 모델 학습을 해야 합니다. 이 글에서는 이미 그 과정은 진행된 상태라는 가정으로 사전학습된 모델을 이용하는 방식으로 진행합니다.
2.환경 구성
2.1. 가상환경 생성
$ conda create -n yolo python=3.11
$ conda activate yolo2.2. Yolov10 다운로드 및 패키지 설치
$ git clone https://github.com/THU-MIG/yolov10
$ cd yolov10
$ pip install .
2.3. 사전 학습 모델 가중치 다운로드
yolov10을 이용해 번호판 감지를 사전 학습한 모델의 가중치 파일은 아래 링크에서 가져옵니다. best.pt 파일을 다운받으면 됩니다.
Computervisionprojects/ANPR_YOLOv10/weights at main · MuhammadMoinFaisal/Computervisionprojects
Computer Vision Projects. Contribute to MuhammadMoinFaisal/Computervisionprojects development by creating an account on GitHub.
github.com
2.4. paddleocr 설치
번호판 영역에서 문제를 인식해서 읽어내는 것으로는 PaddleOCR을 이용하게 되는데 이를 위해 PaddlePaddle이 필요합니다.
$ pip install paddlepaddle==3.0.0b1
$ pip install paddleocr
paddlepaddle의 경우, 현재의 정식 Stable 버전은 2.6인데 그 버전으로 하면 다음과 같은 오류가 발생합니다. 최신 3.0.0b1에서 fix되었다고 해서 그걸로 진행합니다. 참고로 paddlepaddle-gpu도 있지만 3.0.0b1에서는 아직 올라온 것이 없어서 CPU 버전으로 진행했습니다.
----------------------
Error Message Summary:
----------------------
FatalError: `Illegal instruction` is detected by the operating system.
[TimeInfo: *** Aborted at 1708043256 (unix time) try "date -d @1708043256" if you are using GNU date ***]
[SignalInfo: *** SIGILL (@0x7f56e0a1e86a) received by PID 468056 (TID 0x7f56e8434200) from PID 18446744073183291498 ***]
Illegal instruction (core dumped)
2.5. 테스트 용 데이터 다운로드
다음 링크에 올라온 영상 파일 가운데 'carLicence4.mp4' 을 이용합니다. 아무래도 해외 영상이라 나중에 한국 도로 영상을 구할 수 있으면 그걸로도 한번 해 봐야겠습니다.
Computervisionprojects/ANPR_YOLOv10/Resources at main · MuhammadMoinFaisal/Computervisionprojects
Computer Vision Projects. Contribute to MuhammadMoinFaisal/Computervisionprojects development by creating an account on GitHub.
github.com
3.테스트 코드
코드는 아래와 같습니다. PaddleOCR과 EasyOCR 둘 다 테스트를 해 보고 있는데, 흠... PaddleOCR일 때는 결과값이 제대로 나오지 않고 있습니다.
import math
import cv2
import numpy as np
import re
from ultralytics import YOLOv10
from paddleocr import PaddleOCR
import easyocr
# 영상 획득
cap = cv2.VideoCapture("data/carLicence4.mp4")
# Yolov10 모델 로딩
model = YOLOv10("weights/best.pt")
ocr_type = 'paddleocr' # or 'easyocr'
# paddle OCR 모델 로딩
ocr = PaddleOCR(use_angle_cls = True, use_gpu = True, lang="korean")
# easyocr 모델 로딩
reader = easyocr.Reader(["en"])
# frame count 초기화
count = 0
# 번호판의 class Name
className = ["License"]
def easyocr_ocr(frame, x1, y1, x2, y2):
text = ''
frame = frame[y1:y2, x1:x2]
result = reader.readtext(frame)
if result:
text = result[0][-2] # 텍스트가 있는 경우에만 할당
return text
def paddle_ocr(frame, x1, y1, x2, y2):
frame = frame[y1:y2, x1:x2]
result = ocr.ocr(frame, det=False, rec=True, cls=True)
text = ''
if result and isinstance(result[0], list):
detected_texts = []
for line in result[0]:
if isinstance(line, tuple) and len(line) > 1 : # 번호판에서 추출된 값이 있으면
detected_texts.append(f"{line[0]};{line[1]}") # 차량번호;confidence
if detected_texts:
text = detected_texts[0] # 첫 번째 텍스트를 사용
return text
while True:
ret, frame = cap.read()
if ret:
count += 1
results = model.predict(frame, conf=0.45)
# 번호판 화면에 그리기
for result in results:
boxes = result.boxes
for box in boxes:
x1, y1, x2, y2 = box.xyxy[0]
x1, y1, x2, y2 = int(x1), int(y1), int(x2), int(y2)
cv2.rectangle(frame, (x1,y1), (x2,y2), (255,0,0), 2)
classNameInt = className[int(box.cls[0])]
conf = math.ceil(box.conf[0]*100)/100
# 번호판에서 차량번호 읽어오기
label = paddle_ocr(frame, x1, y1, x2, y2)
if not isinstance(label, str):
label = ''
textSize = cv2.getTextSize(label, 0, fontScale=0.5, thickness=2)[0]
c2 = x1 + textSize[0], y1- textSize[1]-3
cv2.rectangle(frame, (x1,y1), c2, (255,0,0), -1)
cv2.putText(frame, label, (x1, y1-2), 0, 0.5, [255,255,255], thickness=1, lineType=cv2.LINE_AA)
print("Bounding Box Coordinates", x1, y1, x2, y2)
cv2.imshow("Video", frame)
if cv2.waitKey(1) & 0xFF == ord('1'):
break
cap.release()
cv2.destroyAllWindows()
4.결과 확인
일단 전반적으로 어느 정도 큰 번호판 감지는 하는 것 같습니다. 아래 사진 보면 뒷 쪽에 있는 차의 경우는 아예 감지를 못합니다.
4.1. EasyOCR을 적용한 경우
EasyOCR을 이용하는 경우는 다음과 같이 나오긴 하는데... 사실 체리피킹이고 지속적으로 OCR한 결과값이 왔다갔다 합니다.

4.2. PaddleOCR을 적용한 경우
PaddleOCR을 적용한 경우는 EasyOCR 대비로는 잘 인식하는 것 같습니다. Confidence 값이 90% 이상을 보여주면 대부분 정확하게 인식해 내는 것을 볼 수 있었습니다. 하지만, 여전히 PaddleOCR에서도 문자 인식하는데 오류가 발생하는 경우는 많이 발생합니다. 학습한 영상과 유사한 상황이 되어야만 제대로 감지하고 인식하고 하는 것 같습니다.


5.테스트 후기
OCR의 성능이 높아지면서 예전처럼 번호판의 글자 하나하나를 CNN 기법으로 분류하던 방식은 이제 사용되지 않을 것 같긴 합니다. 위 테스트 결과만 보더라도 PaddleOCR의 경우는 영어나 중국어, 한국어를 그나마 잘 처리하고 있는 것 같긴 합니다. EasyOCR은 상대적으로 성능이 많이 떨어지는 것으로 보이구요.
하지만, 성능이 높아졌다고 하더라도 OCR 원본 모델의 성능만으로는 특정 도메인 분야에 그래도 적용하는 것은 한계가 있습니다. 번호판 인식만 하더라도 위의 모델을 그대로 도로의 CCTV 영상이나 주행 중 블랙박스에 찍힌 영상을 이용해서 돌려보면 일단 번호판 감지 성능부터, 감지된 번호판의 번호 추출 성능까지 둘 다 상당히 떨어져 이거 쓸만한 수준맞아? 하는 의문을 가지게 되실 겁니다. 그만큼 특정 도메인 분야에는 단순 기술만으로 처리하지 못하는 것을 전처리, 후처리하는 기술, 해당 도메인의 엣지 데이터를 추가로 수집해서 이를 이용한 파인 튜닝하는 기술, 그리고 각 업체마다 가지고 있는 고유의 노하우가 녹아있다는 것을 명심해야 합니다. 하긴 '장난감(절대 폄하 아님!) 만드는 기술'로 상용 서비스를 하려는 곳이 있지는 않겠죠?
이번 글에서는 번호판 인식과 관련해 기존에 공개되어 있는 모델들을 이용해 돌려보는 테스트를 진행했습니다. 다음 번에도 비슷하게 초보자가 한번쯤 따라해볼만한 것으로 내용을 구성해서 보여 드리겠습니다. 즐기는거죠. ^^
참고자료
테스트를 진행하기 위해 둘러본 Github에서 찾은 내용들 가운데 괜찮아 보이는 곳들을 찾아봤습니다.
1. TS-ANPR
국내 업체에서 공개한 오픈소스 기반 솔루션으로 보입니다. 실제 사용하려면 상용 라이선스를 구입해야 하는데 30일 Trial로 테스트는 충분히 진행할 수 있습니다. 국내 자동차 번호판 인식을 위한 아주 다양한 고민을 많이 해서 개발된 제품 같았습니다. 직접 이 솔루션을 사용하지 않더라도 주차나 번호판 인식을 공부하기 위한 용도로라도 꼭 들러서 내용을 보시면 좋을 것 같습니다.
GitHub - bobhyun/TS-ANPR: 🚀 딥러닝 기반 차량번호 인식 엔진
🚀 딥러닝 기반 차량번호 인식 엔진. Contribute to bobhyun/TS-ANPR development by creating an account on GitHub.
github.com
2. SamLP
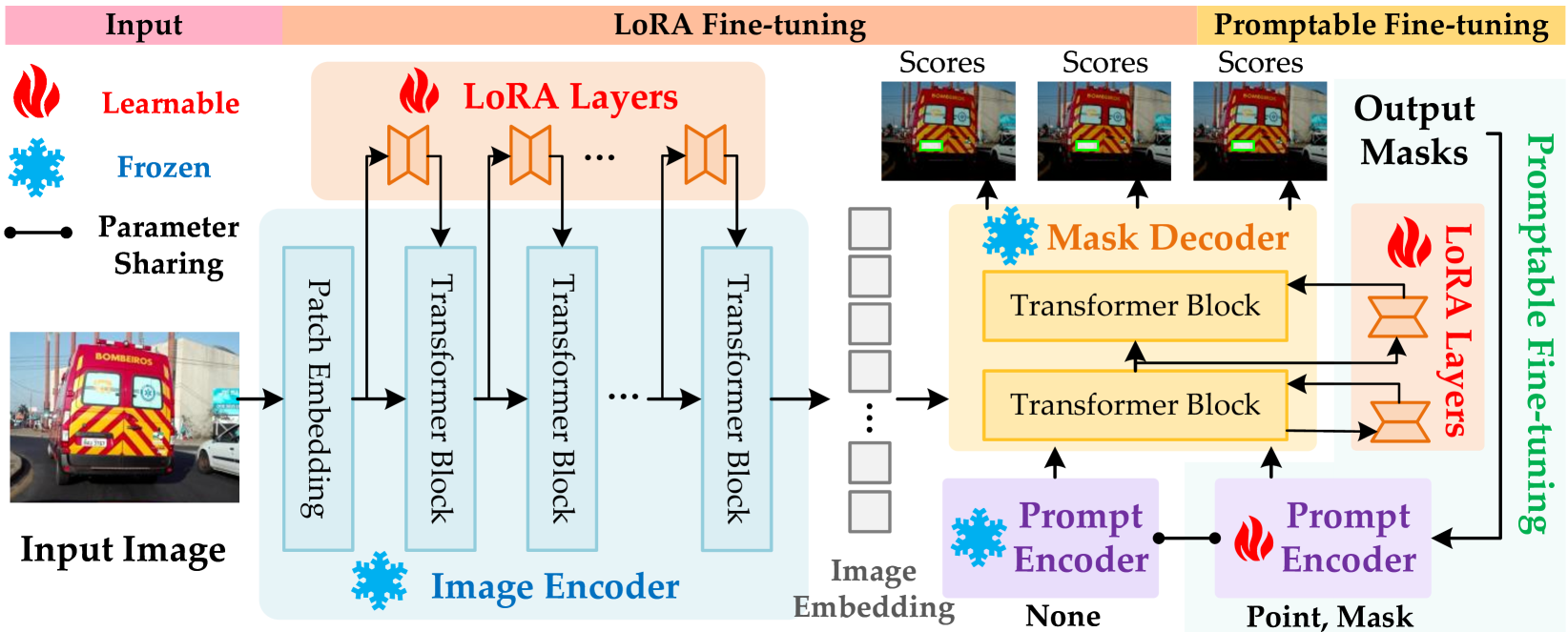
SAM(Segment Anything Model)을 커스터마이징해서 번호판을 감지하는 모델을 만들어 공개한 분이 있었습니다. Few-shot 성능이 타 모델 대비 높은 성능을 보이고 있는데, 아무래도 좀 무거울 것 같아서 이번 글에서는 이를 선택하진 않았습니다. 그래도 관심을 가져볼만 하지 않나 싶습니다.
SamLP: A Customized Segment Anything Model for License Plate Detection
CCPD [70] dataset includes a huge amount Chinese LPs captured in parking lots. The images in CCPD [70] all have a fixed size of 720×1,1607201160720\times 1,160720 × 1 , 160. There are nine subset in CCPD [70] containing different scenes: CCPD-Base (200,0
arxiv.org
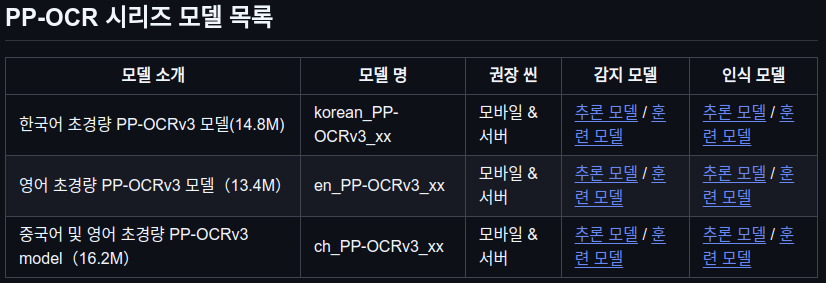
3. PP-OCR(PaddlePaddle-OCR) 한글 지원
PaddleOCR이 중국어, 영어, 그리고 한국어도 제법 잘 처리하고 있다고 알려져 있습니다. 아래 URL 상에는 한국어 초경량 버전(14.8MB)도 제공하고 있습니다. 자동차 번호판이 아니더라도 다른 쪽에 가벼우면서도 성능 좋은 OCR 모듈이 필요할 경우에 활용할만한 솔루션으로 판단됩니다.
PaddleOCR/doc/doc_i18n/README_한국어.md at main · PaddlePaddle/PaddleOCR
Awesome multilingual OCR toolkits based on PaddlePaddle (practical ultra lightweight OCR system, support 80+ languages recognition, provide data annotation and synthesis tools, support training and...
github.com
4. VideoPipe
비전 관련 프로세스를 파이프라인화할 수 있도록 만든 솔루션입니다.
GitHub - sherlockchou86/VideoPipe: A cross-platform video structuring (video analysis) framework. If you find it helpful, please
A cross-platform video structuring (video analysis) framework. If you find it helpful, please give it a star: ) 跨平台的视频结构化(视频分析)框架,觉得有帮助的请给个星星 : ) - GitHub - sherlockchou86/VideoPipe: A cross-plat...
github.com
NVIDIA의 DeepStream이나 Gstremer와 비슷한 컨셉같습니다. 현재는 Linux Foundation의 프로젝트로 진행되고 있는 것으로 삼성전자 연구원들이 만들었던 NNStreamer라는 것도 있었죠.
Home - NNStreamer
NNStreamer provides a set of GStreamer plugins so developers may apply neural networks, attach related frameworks (including ROS, IIO, FlatBuffers, and Protocol Buffers), and manipulate tensor data streams in GStreamer pipelines easily and execute such
nnstreamer.ai
'DIY 테스트' 카테고리의 다른 글
| DeepFace를 이용한 안면 속성 분석 (표정,연령 등) (2) | 2024.10.30 |
|---|---|
| 군중(Crowd) 카운팅 (1) | 2024.10.29 |
| To-Do 리스트 만들어보기 (2) | 2024.10.25 |
| [Roboflow] Soccer AI 실행 테스트 (4) | 2024.10.23 |
| Whisper Turbo 로컬 설치 및 테스트 (4) | 2024.10.22 |



