

| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- 오픈소스
- 오블완
- LORA
- LLM
- 일론 머스크
- XAI
- 확산 모델
- ChatGPT
- 티스토리챌린지
- 메타
- 강화 학습
- 딥러닝
- 우분투
- tts
- OpenAI
- 생성형AI
- 트랜스포머
- 휴머노이드 로봇
- gaussian splatting
- ai 챗봇
- 자연어 처리
- 멀티모달
- 시간적 일관성
- AI
- AI 기술
- 오픈AI
- OpenCV
- PYTHON
- 인공지능
- 실시간 렌더링
- Today
- Total
AI 탐구노트
Whisper Turbo 로컬 설치 및 테스트 본문

Whisper Turbo
Whisper Turbo는 OpenAI에서 개발한 Whipser의 최신 버전입니다. 'Turbo'라는 이름이 붙은 것처럼 높은 정확도에도 불구하고 기존 대비 처리 속도가 대폭 빨라졌습니다. 최대 8배 가까이
환경 구성
1.Anaconda 가상 환경
$ conda create -n whisper python=3.10
$ conda activate whisper
2.pytorch 설치
Whisper Turbo +
1.Flash Attention 2 설치
이 녀석은 추론 속도를 최적화해서 제공하므로 설치하는 것이 좋다고 해서 진행합니다. github repository에는 설치 과정도 아래 딱 한 줄 명령어라 너무 쉽게 생각했던 것 같습니다.
$ pip install flash-attn --no-build-isolation
빌드하는데만 i7 CPU, 32MB, RTX3090, 우분투 24.04에서 대략 2시간 넘게 걸린 것 같습니다. 이게 과연 설치가 되고 있는건가 하는 의심을 100번도 더 한 것 같습니다. 그래도 혹시나 모르니 놔둬보자 했는데 결국은 되긴 하더군요. 빌드 후 install 자체는 오래 걸리지 않았습니다. 그런데... 이렇게 오래 걸릴거면 OS 플랫폼 별로 미리 빌드된 것을 다운받을 수 있도록 해 주면 좋을텐데요... 아쉽습니다. 혹... 저만 이 시행착오를 겪고 있는건 아니겠죠? -_-;
코드
테스트 코드는 다음의 링크에서 사용된 것을 가져왔습니다. 파일 선택 외에도 실시간으로 Mic에서 입력된 음성을 이용할 수 있도록 gradio를 이용해 만든 데모인데, 제가 하려는 테스트 내용과 일치하는 것 같았기 때문입니다.
Realtime Whisper Turbo - a Hugging Face Space by KingNish
Running on Zero
huggingface.co
app.py의 코드 내용은 다음과 같습니다. 맨 윗줄의 Flash Attention 설치 부분은 일단은 코멘트 처리해 두고 진행합니다.
import spaces
import torch
import gradio as gr
import tempfile
import os
import uuid
import scipy.io.wavfile
import time
import numpy as np
from transformers import AutoModelForSpeechSeq2Seq, AutoProcessor, WhisperTokenizer, pipeline
import subprocess
# subprocess.run(
# "pip install flash-attn --no-build-isolation",
# env={"FLASH_ATTENTION_SKIP_CUDA_BUILD": "TRUE"},
# shell=True,
# )
torch_dtype = torch.float16 if torch.cuda.is_available() else torch.float32
MODEL_NAME = "openai/whisper-large-v3-turbo"
model = AutoModelForSpeechSeq2Seq.from_pretrained(
MODEL_NAME, torch_dtype=torch_dtype, low_cpu_mem_usage=True, use_safetensors=True, attn_implementation="flash_attention_2"
)
# Check if GPU is available
device = "cuda" if torch.cuda.is_available() else "cpu"
model.to(device)
processor = AutoProcessor.from_pretrained(MODEL_NAME)
tokenizer = WhisperTokenizer.from_pretrained(MODEL_NAME)
pipe = pipeline(
task="automatic-speech-recognition",
model=model,
tokenizer=tokenizer,
feature_extractor=processor.feature_extractor,
chunk_length_s=10,
torch_dtype=torch_dtype,
device=device,
)
@spaces.GPU
def transcribe(inputs, previous_transcription):
start_time = time.time()
try:
filename = f"{uuid.uuid4().hex}.wav"
sample_rate, audio_data = inputs
scipy.io.wavfile.write(filename, sample_rate, audio_data)
transcription = pipe(filename)["text"]
previous_transcription += transcription
end_time = time.time()
latency = end_time - start_time
return previous_transcription, f"{latency:.2f}"
except Exception as e:
print(f"Error during Transcription: {e}")
return previous_transcription, "Error"
@spaces.GPU
def translate_and_transcribe(inputs, previous_transcription, target_language):
start_time = time.time()
try:
filename = f"{uuid.uuid4().hex}.wav"
sample_rate, audio_data = inputs
scipy.io.wavfile.write(filename, sample_rate, audio_data)
translation = pipe(filename, generate_kwargs={"task": "translate", "language": target_language} )["text"]
previous_transcription += translation
end_time = time.time()
latency = end_time - start_time
return previous_transcription, f"{latency:.2f}"
except Exception as e:
print(f"Error during Translation and Transcription: {e}")
return previous_transcription, "Error"
def clear():
return ""
with gr.Blocks() as microphone:
with gr.Column():
gr.Markdown(f"# Realtime Whisper Large V3 Turbo: \n Transcribe Audio in Realtime. This Demo uses the Checkpoint [{MODEL_NAME}](https://huggingface.co/{MODEL_NAME}) and 🤗 Transformers.\n Note: The first token takes about 5 seconds. After that, it works flawlessly.")
with gr.Row():
input_audio_microphone = gr.Audio(streaming=True)
output = gr.Textbox(label="Transcription", value="")
latency_textbox = gr.Textbox(label="Latency (seconds)", value="0.0", scale=0)
with gr.Row():
clear_button = gr.Button("Clear Output")
input_audio_microphone.stream(transcribe, [input_audio_microphone, output], [output, latency_textbox], time_limit=45, stream_every=2, concurrency_limit=None)
clear_button.click(clear, outputs=[output])
with gr.Blocks() as file:
with gr.Column():
gr.Markdown(f"# Realtime Whisper Large V3 Turbo: \n Transcribe Audio in Realtime. This Demo uses the Checkpoint [{MODEL_NAME}](https://huggingface.co/{MODEL_NAME}) and 🤗 Transformers.\n Note: The first token takes about 5 seconds. After that, it works flawlessly.")
with gr.Row():
input_audio_microphone = gr.Audio(sources="upload", type="numpy")
output = gr.Textbox(label="Transcription", value="")
latency_textbox = gr.Textbox(label="Latency (seconds)", value="0.0", scale=0)
with gr.Row():
submit_button = gr.Button("Submit")
clear_button = gr.Button("Clear Output")
submit_button.click(transcribe, [input_audio_microphone, output], [output, latency_textbox], concurrency_limit=None)
clear_button.click(clear, outputs=[output])
with gr.Blocks(theme=gr.themes.Ocean()) as demo:
gr.TabbedInterface([microphone, file ], ["Microphone", "Transcribe from file"])
demo.launch()
테스트
위의 코드를 실행해 줍니다. 대략 2GB 가량의 GPU 메모리를 사용하는 것 같고 생각보다 가볍게 동작합니다.
$ python app.py
You are attempting to use Flash Attention 2.0 with a model not initialized on GPU. Make sure to move the model to GPU after initializing it on CPU with `model.to('cuda')`.
* Running on local URL: http://127.0.0.1:7860
To create a public link, set `share=True` in `launch()`.
서버가 구동되면 로그에 표시되는 URL을 클릭해서 브라우저에서 열어 줍니다.
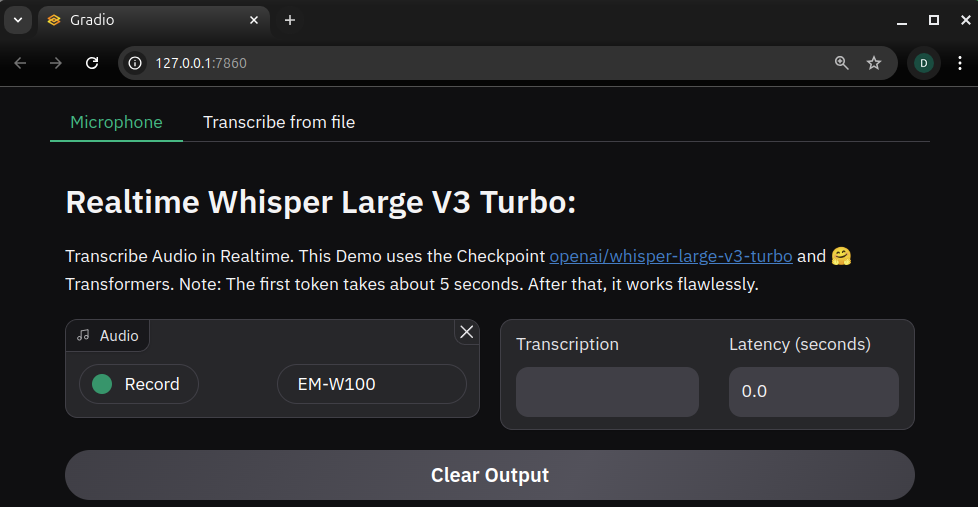
결과 확인
테스트에 사용한 문구는 헤르만 헤세의 데미안에 나오는 것으로 해 봤습니다.
"모든 인간은 자기 자신으로부터 시작하여 다른 사람과 연결되기 위해 끊임없이 투쟁한다. 우리는 진정한 나를 발견하기 전에는 그 어떤 사람과도 진정한 만남을 가질 수 없다. 따라서 인생의 여정은 자기 자신을 찾기 위한 고독한 여행일 뿐만 아니라, 그 여행을 통해 세계와 조화롭게 연결되는 길을 찾는 여정이기도 하다."
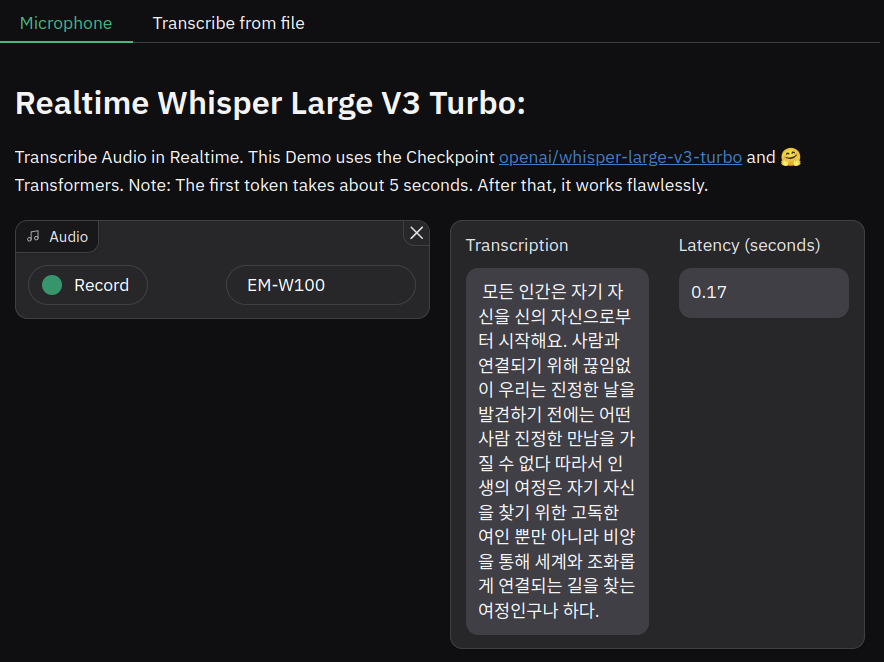
Whisper Turbo는 생각보다 빠른, 거의 실시간에 가까운 속도로 말을 기록해 주었습니다. 다만, 아래 내용을 보면 내용이 누락되거나 이상하게 기록된 것을 볼 수 있는데, 이는 제 목소리가 이상하거나 주변 잡음의 영향이었다고 할 수는 없을 정도인 것 같습니다. 독립된 밀폐 공간에서 진행한 것이라 그렇게 생각됩니다. 혹시나 주변 잡음 때문인가, 아니면 블루투스 헤드셋의 Output으로 나오는 소리가 영향을 미치나 해서 잡음도 없애고 소리 아웃풋도 끄고 진행해 봤지만 결과는 비슷했습니다. 흠... 뭐가 문제일까?
여러 번 시도해봤지만 결과는 비슷했습니다. 모델 자체의 성능 문제인 것 같기도 하고 그렇지 않은 것 같기도 하고 참 헷갈립니다.
모든 인간은 자기 자신을 시작하여 다른. 감사합니다. 우리는 진정한 나라를 발견하기 전에는 그 어떤 사람과도 진정한 만남을 가질 수 없다 따라서 인생의 여정은 고독한 자녀를 만나면 그 여행을 통해서 세계와 조화롭게 연결되는 길을 참는 여정이기도 하다.
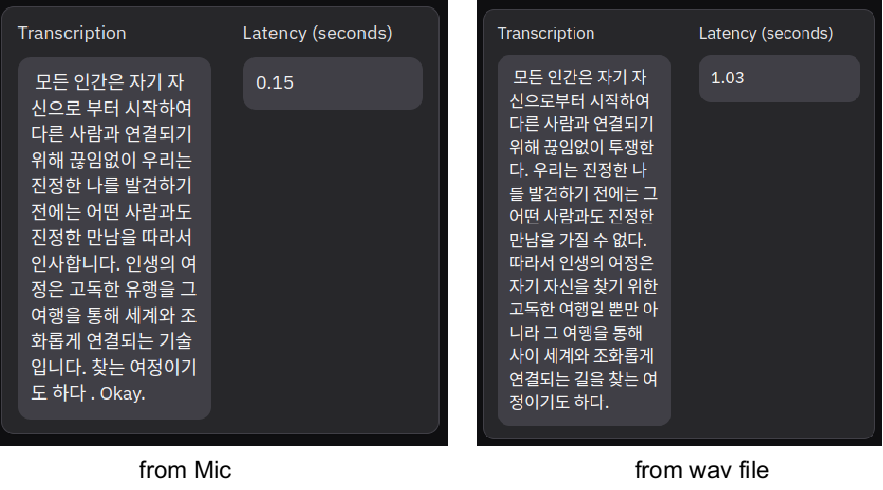
예를 들어 거의 동일한 (녹음 & 저장을 함께 하진 않았음 ^^;) 수준으로 진행한 사례에서 위와 같은 결과가 나왔습니다. 파일에서 하면 아주 잘 한다, 다만 약간 시간이 더 걸릴 뿐이다. 마이크에서 스트림 방식으로 하면 빠르지만 결과가 좋지 않다 이런 결론 같습니다.
개선방안
이런 차이가 나는 이유를 몇 가지 생각해 봤고 일부는 테스트를 진행해 봤습니다.
- 마이크 입력 시 주변 잡음 등 음성 품질 요인
-> 실시간 마이크 음성을 그대로 녹음한 파일로 비교했으므로 아닐 듯 싶긴 하나 분명히 다양한 음성에 대해서는 좋을 듯 - 스트리밍 또는 실시간 처리의 한계?
스트리밍 데이터의 길이가 짧거나 불완전한 경우, Whisper가 실시간 결과 예측을 하기 힘들 수도 있음
-> 가능하지만, 실제 문장 자체가 짧지도 않고 단락단락 끊어서 한 것도 아닌데... 그래도 향후에 단어 단위 등으로 자를 수 있다면 혹은 버퍼링을 이용해 개선 가능하지 않을까 생각됨 - 음성 데이터 샘플링 속도 문제
샘플링 속도가 마이크인 경우, 파일인 경우가 다를 수도 있다고 함
-> gradio는 기본 sample_rate값이 기본 44100Hz로 되어 있는 것 같고, Whisper는 16000 Hz를 사용한다니 그걸로 조정해서 테스트 해 볼 수도 있겠다 싶어 librosa를 이용해 16000Hz로 resample 해봤지만 결과는 크게 다르지 않음. - 모델의 초기 지연 시간
첫번째 토큰 생성 시 지연시간으로 인한 누락 가능성인데... 현재 테스트 결과에선 앞 부분 누락보다 중간 부분 누락이 대부분임 - 오디오 스트리밍 및 처리 동기화 문제
오디오 스트리밍과 모델 전달 시점 사이의 동기화(?) 문제가 발생할 수 있으니 모델 전달 전 버퍼링하는 방안을 검토해 보라고 합니다. 이 부분은 잘 이해가 안 되어 패스~ - gradio의 스트리밍 설정 문제
streaming=True 옵션 사용 시 스트리밍 세그먼트의 길이나 타이밍 문제가 발생할 수 있으므로, stream_every 파라미터를 조절해 스트리밍 세그먼트의 길이를 늘이는 것을 검토하라고 합니다. 약간 일리가 있어 보입니다.
-> stream_every 값은 stream chunk가 백엔드 모델로 전달되기까지의 latency로 기본값은 0.5입니다. 이 값을 3,5,10 등으로 늘려봤는데 값이 커질수록 기록되는 내용은 기존보다 나아졌습니다. 다만, 결과물 표시 자체의 지연이 발생하고, 중간중간 생기던 누락도 여전히 존재합니다. stream_every와 pipeline의 chunk_length_s 값을 서로 조절해주니 결과가 더 나아지는 부분들이 생깁니다. 하지만, 이런 매개변수 최적값에 대해서는 어떤 원칙이 있지 않을까 싶은데 수작업으로 찾아가는 과정이 못 마땅해 일단 이 정도 확인하는 선에서 멈춥니다. 제 경우, chunk_length_s=40, stream_every=4로 하고 음성 속도가 약간 느린 수준으로 진행했을 때 그나마 괜찮게 나왔습니다.
후기
이번 테스트에서 가장 시간이 많이 걸린 부분은 Flash Attention 2의 빌드였던 것 같습니다. 빌드, 설치가 정상적으로 되고 나서도 코드에서 이를 활용하는 것에는 시행착오가 있었습니다. 사용하면 좋아진다고 해서 했던건데 과정이 험난해서... 서비스를 상용화할 때나 해볼만한 일 같습니다. 또 모르죠. 다른 분들은 너무 쉽게 진행했다고 하실지...
그리고, 마이크를 통해 스트리밍되는 음성을 바로 처리하는 것은 제공되는 코드를 그냥 쓴다고해서 답이 나오는 작업은 아니란 것은 알고 있었지만, 간단한 장난감 하나 만들기 위한 수준의 결과물을 얻는 것도 전처리, 후처리 등 해야할 작업이 많다는 것을 알게 됐습니다.
다음 번에는 이 기능들을 다른 것과 엮어서 또 다른 재미난 것을 하나 만들어보겠습니다.
참고 자료
해보면서 찾아본 내용들도 함께 공유해 봅니다.
1.Gradio Audio 컴포넌트 사용법
Gradio를 이용해 데모를 생성할 때 오디오 입력을 처리하는 방법에 대한 문서입니다.
Gradio Docs
Gradio docs for using
www.gradio.app
추가로, Streaming Inputs에 대한 forum 내용 (링크)도 참고하세요.
2.Fine tune and Serve Faster Whisper Turbo
Whisper Turbo + Faster Whisper + 커스텀 데이터를 이용한 Fine Tunning 을 설명하는 튜토리얼 영상입니다. 나중에 자체 데이터를 가지고 있고 이를 활용해서 파인튜닝을 해 보고 싶을 때 다시 한번 들여다 볼 생각입니다.
3.whisper-turbo
Whisper Turbo를 WebGPU를 이용해 처리하는 프로젝트입니다. 코드는 typescript로 되어 있고 node.js를 이용해 서비스 합니다.
GitHub - FL33TW00D/whisper-turbo: Cross-Platform, GPU Accelerated Whisper 🏎️
Cross-Platform, GPU Accelerated Whisper 🏎️. Contribute to FL33TW00D/whisper-turbo development by creating an account on GitHub.
github.com
4.성능 최적화를 위한 Flash-Attention 2
Attention 및 Flash Attention 2에 대한 설명이 되어 있습니다. 저한테는 복잡한 내용이라 슥... 아 그래서 좋은거구나 하면서 넘어갑니다.
성능 최적화를 위한 Flash Attention 2
기존의 PyTorch의 Attention 연산 대비 10배 빠른 Flash Attention 2
taewan2002.medium.com
'DIY 테스트' 카테고리의 다른 글
| To-Do 리스트 만들어보기 (2) | 2024.10.25 |
|---|---|
| [Roboflow] Soccer AI 실행 테스트 (4) | 2024.10.23 |
| Whisper를 이용한 실시간 음성인식 (6) | 2024.10.18 |
| ComfyUI에서 CivitAI LoRA 사용해 보기 (6) | 2024.10.16 |
| Headshot Tracking 따라하기 - 2편 (8) | 2024.10.14 |



