

| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- 딥러닝
- tts
- 메타
- 티스토리챌린지
- 확산 모델
- gaussian splatting
- OpenCV
- AI
- LLM
- 오픈AI
- 오블완
- 인공지능
- 우분투
- 시간적 일관성
- 트랜스포머
- 자연어 처리
- XAI
- 일론 머스크
- 오픈소스
- 생성형AI
- PYTHON
- 휴머노이드 로봇
- 멀티모달
- ai 챗봇
- 실시간 렌더링
- 강화 학습
- ChatGPT
- LORA
- OpenAI
- AI 기술
- Today
- Total
AI 탐구노트
Transformer2 : 새로운 태스크에 실시간으로 적응하는 똑똑한 언어 모델 본문

요즘 우리가 쓰는 챗봇이나 번역기 같은 AI는 대규모 언어 모델(LLM)이라는 기술을 활용해 작동합니다. 하지만 이 모델들은 이미 학습된 고정된 학습 결과물을 바탕으로 작동하기 때문에 새로운 주제나 문제가 주어질 때 쉽게 적응하지 못합니다. 만약 새로운 태스크나 데이터 도메인에 적응하도록 만들려면 높은 비용의 재학습 과정이 필요하죠. 이러한 한계를 극복하기 위해, 연구자들은 더욱 효율적이고 유연한 적응 가능성을 탐구하고 있습니다.
Transformer2라는 기술은 이러한 문제를 해결하기 위해 고안되었습니다. 이 기술은 기존 모델을 다시 학습시키지 않고도 새로운 문제에 적응할 수 있는 '자가조정(Self-adaptive)' 기능을 가지고 있어 실시간으로 새로운 태스크에 적응할 수 있는 프레임워크를 제공합니다. 특히 모델 가중치의 일부만 선택적으로 조정하여, 더 적은 컴퓨팅 자원으로도 효율적으로 작동합니다.
기존 LLM 학습 방식의 문제점
기존 LLM 학습은 다음과 같은 한계를 가지고 있었습니다.
- 재학습 비용이 너무 큼 : 기존 모델을 새로 학습시키려면 엄청난 시간과 컴퓨팅 자원이 필요합니다.
- 다양한 문제에 잘 적응하지 못함 : 기존 모델은 처음 학습한 문제들만 잘 처리하고, 새로운 문제에는 취약합니다.
- 여러 문제를 처리하려다 성능 저하 : 하나의 모델로 여러 문제를 처리하려다 보면 성능이 떨어질 수 있습니다.
Transformer2의 접근 방식
Transformer2는 다음 두 가지 핵심 아이디어를 기반으로 설계되었습니다.
- 단일 값 세분화(Singular Value Fine-tuning, SVF)
- 모델의 전체를 바꾸는 대신, 특정한 중요한 부분만 조정합니다. 즉, 모델의 가중치 행렬을 특이값 분해(SVD)로 표현하고, 성분별로 조정 가능한 벡터를 학습하는 것인데, 이는 기존의 전체 가중치 조정 방식보다 효율적이며, 과적합을 방지합니다.
- 2단계 추론 메커니즘
- 첫 번째 단계 : 태스크의 특성을 분석해 그것에 적합한 '전문가 벡터'를 선택합니다.
- 두 번째 단계 : 선택된 벡터를 활용해 모델을 재구성하고, 최적의 결과를 생성합니다.
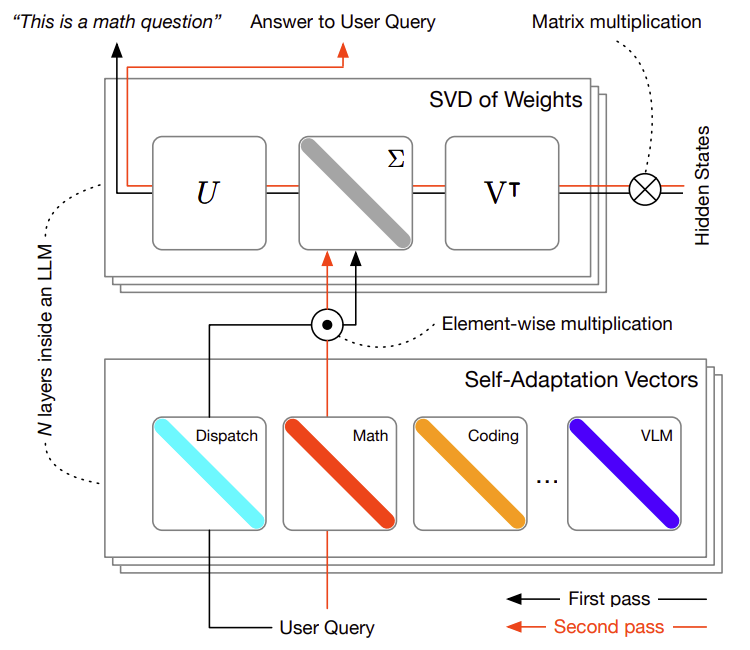
아래 그림은 Transformer2가 동작하는 방식을 보여주고 있습니다. 학습 단계에서는 다양한 태스크 별로 '전문가 벡터'를 생성하고 추론 단계에서는 '어떤 문제인지 분석'하고 '적절한 전문가 벡터를 선택'해 답을 생성하는 2단계 추론을 수행합니다.

좌측 그림에서 'Frozen Parameters'라고 되어 있는 부분이 모델의 고정된 가중치를, 'Learnable Parameters'가 조정 가능한 SVF 벡터를 나타냅니다.
우측 그림에서는 질문 유형을 분석해 SVF 벡터를 선택 혹은 결합하는 방식으로 진행되는데 이 때 3가지 적응(adaptation) 방식으로 프롬프트 기반, 분류기 기반, 혼합 기반이 사용됩니다.
Transformer2의 주요 기술 설명
1) SVF(Singular Value Fine-tuning, 특이값 기반 미세 조정)
- 효율성 : SVF는 모델 가중치에서 중요한 성분만을 선택적으로 학습하여, 필요한 파라미터 수를 크게 줄입니다.
- 해석 가능성 : 조정된 벡터가 모델의 동작을 명확히 설명할 수 있도록 구성됩니다.
- 정규화 효과 : 기존 정보 구조를 유지하면서 조정되므로, 데이터 부족 시에도 과적합이 방지됩니다.
2) 강화 학습 (RL) 기반 최적화
- SVF 벡터를 강화 학습으로 학습하며, 정확도를 기준으로 보상을 제공합니다.
- 기존 모델 동작과의 편차를 최소화하는 정규화 용어를 포함하여 안정성을 높입니다.
3) 2단계 적응 전략
- 문제 프롬프트 기반 분류 : 입력된 태스크를 분류하여 코드, 수학문제, 논리문제 등으로 구분합니다. 이때 태스크 분류를 전담하는 모듈을 활용하여 적응성을 높입니다.
- 전문가 벡터 사용 : 적합한 전문가 벡터를 선택하거나 여러 벡터를 결합하여 복잡한 태스크에도 대응합니다.
Transformer2의 제약사항
- 데이터 의존성 : SVF 벡터의 성능은 학습 데이터의 품질에 크게 좌우됩니다. 즉, 학습 데이터가 부족하거나 품질이 낮으면 성능이 떨어질 수 있습니다.
- 태스크 분류 정확도: 분류 과정에서 잘못된 벡터가 선택되면 성능 저하가 발생할 수 있습니다.
정리하며
Transformer2는 기존 언어 모델의 한계를 극복하며, 새로운 문제를 실시간으로 처리할 수 있는 가능성을 열었습니다. 게다가 SVF를 활용한 효율적인 조정과 2단계 적응 메커니즘 덕분에 다양한 분야에서 효과적으로 사용할 수도 있습니다.
앞서 Transformer2에서 보여준 가능성은 '스스로 진화하는 AI'와 '사용자 별 개인화된 경험'이라는 용어로 연결되는 것 같습니다. 이러한 기술이 고도화된다면, 스스로 조정 가능해지므로 AI가 정적인 시스템이 아니라 동적인 시스템으로 진화할 수 있겠고, 사용자가 하는 질문 내용에 따라서 가장 적합한 답변을 찾고 사용자 스타일과 요구에 맞도록 최적화된 정보를 제공할 수 있어 개인 비서같은 존재가 될 수도 있겠죠. 어디까지나 상상의 나래를 펼쳐본다면 말입니다. ^^
참고자료
- Transformer2: Self-Adaptive LLMs 논문 (링크)
- Transformer2 GitHub 저장소 (링크)
- Transformer2에 대한 Sakana.ai의 블로그 (링크)
Q&A
Q. Transformer2의 주요 개선점은 무엇인가요?
태스크별로 가중치를 실시간으로 조정하며, 기존보다 적은 자원으로 높은 성능을 달성합니다.
Q. SVF와 기존 LoRA 방식의 차이점은 무엇인가요?
SVF는 특이값만 조정하여 파라미터 수를 크게 줄이며, 고유의 정규화 효과로 과적합을 방지합니다.
Q. 이 기술이 적용 가능한 실제 사례는 어떤 것들이 있나요?
실시간 고객 상담, 코드 생성, 또는 시각적 질문 응답 시스템에 활용될 수 있습니다.
'AI 기술' 카테고리의 다른 글
| Google's Gemini 2.0의 Stream Realtime (1) | 2025.01.21 |
|---|---|
| MatterGen : 생성 AI를 활용한 무기 재료 설계의 새로운 패러다임 (0) | 2025.01.20 |
| Replicate : 오픈소스 AI모델을 이용하는 새로운 방법을 제시하는 플랫폼 (1) | 2025.01.17 |
| AI 이미지 생성 모델 비교 : 어떤 것이 가장 적합한가? (0) | 2025.01.17 |
| Sky-T1 : $450 이하로 구현한 고성능 추론 모델 (0) | 2025.01.16 |



