

| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- 실시간 렌더링
- ai 챗봇
- OpenAI
- 오블완
- LORA
- 일론 머스크
- 시간적 일관성
- ChatGPT
- AI 기술
- 티스토리챌린지
- OpenCV
- 우분투
- 휴머노이드 로봇
- LLM
- 트랜스포머
- 다국어 지원
- AI
- 멀티모달
- 오픈소스
- 인공지능
- 강화 학습
- tts
- 자연어 처리
- 메타
- 딥러닝
- 오픈AI
- 생성형AI
- 확산 모델
- PYTHON
- XAI
- Today
- Total
AI 탐구노트
OmniParser : UI 스크린샷을 구조화된 요소로 변환하는 기술 본문

1.서론
최근, 데스크톱 화면의 스크린샷을 AI가 이해하고 파싱하는 기술이 주목받고 있습니다. 이 기술은 단순한 이미지 인식에서 나아가 화면에 보이는 텍스트와 레이아웃, 심지어 사용자의 클릭 패턴까지 분석합니다. 이를 통해 AI는 인간의 디지털 환경을 더 깊이 이해하며, 문서 작업의 자동화나 특정 작업 흐름을 모니터링하는 등 다양한 업무 지원에 활용될 수 있습니다. 특히, 기업의 IT 지원이나 데이터 입력 작업에서 효율성을 크게 높일 수 있다는 점에서 실용성이 기대됩니다.
하지만 이러한 기술이 발전할수록 ‘직업 대체’에 대한 우려도 커지고 있습니다. AI가 업무를 더 잘 이해하고 처리하게 될수록 인간이 맡아온 일의 일부가 점차 자동화될 가능성이 있다는 것입니다. 특히 반복적이고 패턴이 명확한 업무는 AI에게 적합한 분야로 꼽히죠. 이에 따라 많은 이들이 자신의 업무가 AI에 의해 대체될 수 있다는 불안감을 느끼고 있습니다.
한편, 이런 변화를 긍정적으로 보는 시각도 있습니다. 인간의 업무 방식과 환경을 이해하는 AI는 그만큼 인간을 효과적으로 도울 수 있는 도구가 된다는 것입니다. 단순히 업무를 대체하는 것이 아니라, 반복적이고 시간 소모적인 작업을 줄임으로써 사람들이 더 창의적이고 전략적인 업무에 집중할 수 있도록 돕는 것이죠. 이는 단순 자동화를 넘어, 인간과 AI가 공존하며 시너지를 내기 위한 자연스러운 단계로 해석될 수 있습니다.
결국, AI의 역할은 인간의 일을 빼앗기 위한 것이 아니라, 인간이 더 나은 결정을 하고 창의적인 문제 해결에 집중할 수 있도록 돕는 데 있습니다. AI가 데스크톱 화면을 파싱하고 이해하는 기술은 그 과정에서 작은 단추일 뿐입니다. 기술의 발전과 인간의 역할 사이에서 균형을 찾는 것, 그것이 우리에게 남겨진 과제일 것입니다.
2.기술
2.1.기존 방식의 문제점
기존의 GPT-4V 기반 모델은 스크린샷에서의 작업 위치(예: 버튼 클릭 위치)를 정확히 파악하지 못해 작업 예측이 부정확했고, 그 때문에 HTML이나 DOM 정보 같은 추가 데이터에 의존하게 되어 플랫폼이나 애플리케이션 간의 일반화가 어려웠습니다.
2.2.OmniParser란
OmniParser는 UI 스크린샷을 구조화된 요소로 변환하여, GPT-4V의 사용자 인터페이스 작업 성능을 개선하는 순수 비전 기반 화면 파싱 기술입니다. 주어진 화면 스크린샷에서 다양한 요소들의 의미를 파악하고 이를 수행할 해당 영역과 정확하게 연결시킬 수 있는 화면 구문 분석 기술인 것이죠. 이 기술은 향후 비전 기반의 지능형 GUI 에이전트 개발에 활용될 수 있습니다.
2.3.OmniParser의 기술 요소
OmniParser는 순수 비전 기반 접근법으로 다음 두 가지 모델을 활용합니다.
- 아이콘 탐지 모델 : UI 스크린샷에서 상호작용 가능한 요소(버튼, 아이콘 등)의 위치를 바운딩 박스로 감지
- 기능 설명 모델 : 탐지된 요소의 기능을 설명하여, 사용자의 작업 의도를 더 잘 이해하도록 지원
OmniParser는 스크린샷 입력을 받아, 탐지된 상호작용 가능한 요소 (버튼, 아이콘) 위에 바운딩 박스와 ID를 겹쳐 표시합니다. 동시에 OCR 모듈로 텍스트를 추출하고, 아이콘 기능 설명 모델을 통해 각 요소의 기능을 파악합니다. 이를 통해 UI 화면을 구조화된 데이터로 변환합니다.
- 입력 : 사용자 작업 설명과 UI 스크린샷
- 출력 : 바운딩 박스가 표시된 스크린샷과 각 요소의 텍스트 설명
2.4.OmniParser의 특징
OmniParser 기술의 특징은 다음과 같습니다.
- 상호작용 가능 영역 탐지 : 스크린샷에서 상호작용할 수 있는 버튼이나 아이콘의 위치를 정확히 식별
- 로컬 기능 의미 통합 : 탐지된 요소의 기능을 설명하는 로컬 의미 정보를 추가로 제공하여, 모델이 각 요소의 역할을 명확히 이해하도록 보조
- 순수 비전 기반 접근 : HTML, DOM 등 추가 정보 없이도 다양한 플랫폼(웹, 모바일, 데스크톱)에서 사용 가능
- 향상된 성능 : ScreenSpot, Mind2Web, AITW 등의 벤치마크에서 기존 GPT-4V 대비 높은 성능을

2.6.OmniParser 적용 예시
단순히 어플리케이션이나 브라우저에 국한되지 않으며 탐색기나 기타 다른 도구에서도 동일하게 적용됩니다. 물론 모바일 화면에서도 동작합니다.
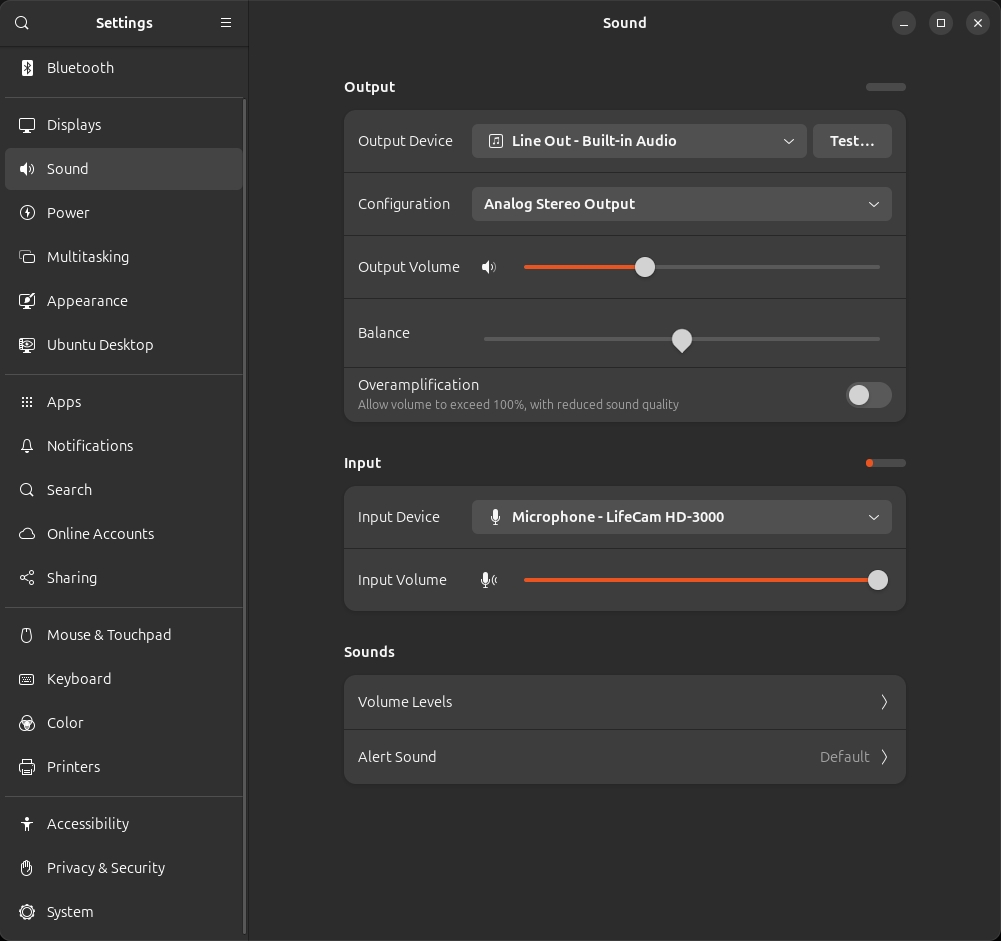
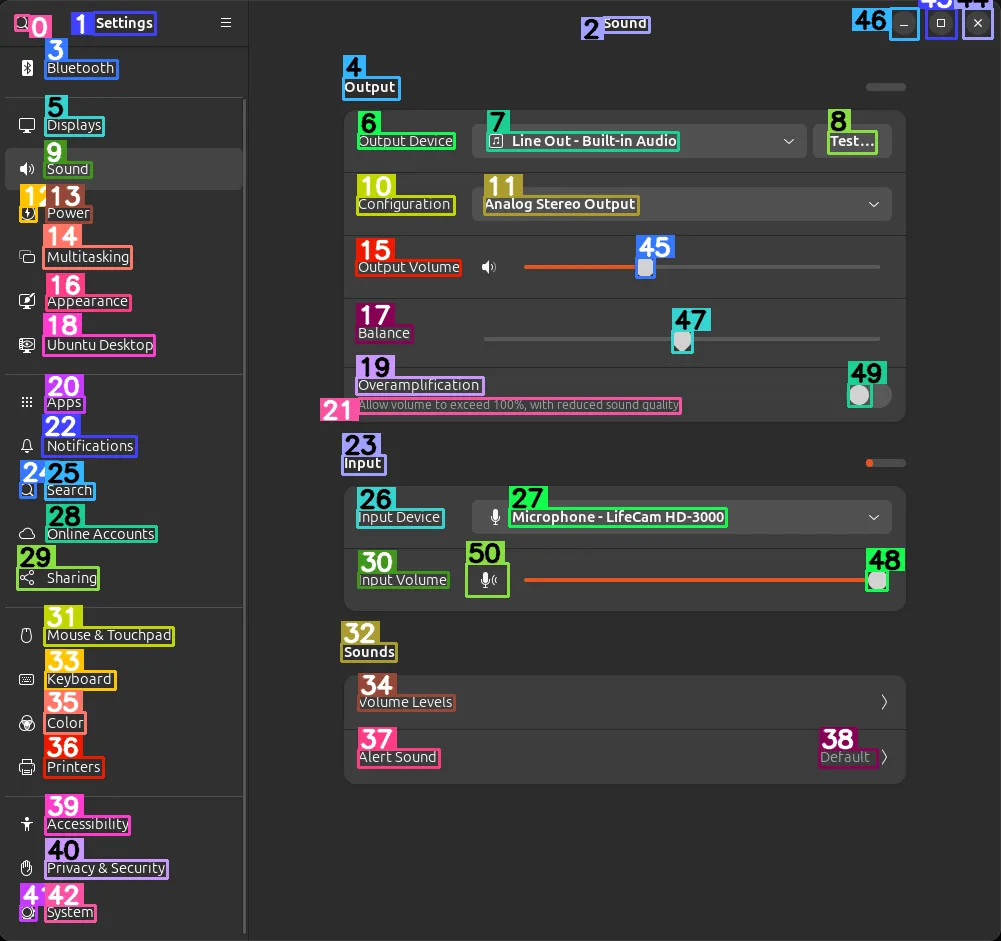
감지된 영역의 ID 별 속성 및 값은 다음과 같습니다. 돋보기 아이콘이 'Q'로 인식되거나 하는 오감지 경우도 많이 발생합니다. 일단은 감지된 영역의 바운딩박스 처리와 해당 영역에 대한 설명은 상당한 수준으로 제공되는 것으로 보입니다.
Text Box ID 0: Q
Text Box ID 1: Settings
Text Box ID 2: Sound
Text Box ID 3: Bluetooth
Text Box ID 4: Output
Text Box ID 5: Displays
Text Box ID 6: Output Device
Text Box ID 7: Line Out - Built-in Audio.
Text Box ID 8: Test...
Text Box ID 9: Sound
Text Box ID 10: Configuration
Text Box ID 11: Analog Stereo Output.
Text Box ID 12: O
Text Box ID 13: Power
Text Box ID 14: Multitasking
Text Box ID 15: Output Volume
Text Box ID 16: Appearance
Text Box ID 17: Balance
Text Box ID 18: Ubuntu Desktop
Text Box ID 19: Overamplification
Text Box ID 20: Apps
Text Box ID 21: Allow volume to exceed 100%, with reduced sound quality
Text Box ID 22: Notifications
Text Box ID 23: Input
Text Box ID 24: Q
Text Box ID 25: Search
Text Box ID 26: Input Device
Text Box ID 27: Microphone - LifeCam HD-3000
Text Box ID 28: Online Accounts
Text Box ID 29: Sharing
Text Box ID 30: Input Volume
Text Box ID 31: Mouse & Touchpad
Text Box ID 32: Sounds
Text Box ID 33: Keyboard
Text Box ID 34: Volume Levels
Text Box ID 35: Color
Text Box ID 36: Printers
Text Box ID 37: Alert Sound
Text Box ID 38: Default
Text Box ID 39: Accessibility
Text Box ID 40: Privacy & Security
Text Box ID 41: O
Text Box ID 42: System
Icon Box ID 43: Maximize
Icon Box ID 44: Close
Icon Box ID 45: a user profile or account.
Icon Box ID 46: Minimize
Icon Box ID 47: Location or place marker.
Icon Box ID 48: a progress bar.
Icon Box ID 49: a loading or buffering indicator.
Icon Box ID 50: Dictate
3.결론
마이크로소프트가 공개한 OmniParser는 사용자의 일상적인 업무를 지원하는 AI 에이전트와 시너지를 창출할 수 있습니다. 화면 구문 분석을 통해 상황을 실시간으로 파악하고, 필요한 정보를 즉시 제공하거나 적합한 작업을 제안할 수도 있을 겁니다. 예를 들어, 고객 관리 시스템을 사용하는 직원을 지원하는 AI는 사용자가 열어본 화면을 분석해 적합한 응답이나 추가 데이터를 추천하는 것 같이 말입니다. 이런 기술적 연계를 통해 인간의 의도와 목적을 제대로 이해하게 되면 결국 AI가 인간을 위해 해 줄 수 있는 역할이 훨씬 많아지겠죠. 직업 대체라는 우려보다 저는 긍정적인 방향의 '가능성'을 더 높게 치겠습니다. ^^
참고자료
1.프로젝트 사이트
마이크로소프트의 OmniParser 사이트입니다.
SOCIAL MEDIA TITLE TAG
SOCIAL MEDIA DESCRIPTION TAG TAG
microsoft.github.io
2.코드 (깃헙)
라이선스는 CC-BY-4.0을 따르고 있습니다.
GitHub - microsoft/OmniParser: A simple screen parsing tool towards pure vision based GUI agent
A simple screen parsing tool towards pure vision based GUI agent - microsoft/OmniParser
github.com
3.데모 (허깅페이스)
위에 보여드린 예시는 아래 허깅페이스 데모 페이지를 이용한 것입니다.
OmniParser demo - a Hugging Face Space by microsoft
Running on Zero
huggingface.co
'AI 기술' 카테고리의 다른 글
| X-Portrait 2 : 자연스럽고 사실적인 얼굴 애니메이션 생성 기술 (5) | 2024.11.09 |
|---|---|
| SplatOverflow : 비동기 원격 하드웨어 트러블 슈팅 기술 (1) | 2024.11.08 |
| HOVER : 여러 제어 방식을 통합한 범용 신경망 기반 전체 신체 제어기 (4) | 2024.11.05 |
| LayerSkip : 더 빠른 추론을 위한 레이어 건너뛰기와 자가 추론 방식 (2) | 2024.11.04 |
| Waffle : UI 디자인을 HTML 코드로 바꿔주는 기술 (2) | 2024.11.02 |



