

| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 |
- AI 기술
- 이미지 편집
- 생성형 AI
- 우분투
- ubuntu
- 오블완
- 일론 머스크
- OpenAI
- javascript
- 메타
- 오픈AI
- TRANSFORMER
- PYTHON
- 멀티모달
- 트랜스포머
- ControlNet
- LLM
- AI
- 서보모터
- 가상환경
- 인공지능
- tts
- ChatGPT
- 시간적 일관성
- 티스토리챌린지
- 아두이노
- LORA
- 딥마인드
- 뉴럴링크
- 확산 모델
- Today
- Total
AI 탐구노트
EMO : 오디오 기반 초상화 비디오 생성 본문
알리바바 그룹이 공개한 오디오 기반 초상화(portrait) 비디오 생성 프레임워크
EMO (Emote Portrait Alive)는 알리바바 그룹이 공개한 오디오 기반 초상화(portrait) 비디오 생성 프레임워크입니다.
참조 이미지 한장과 보컬 오디오 클립을 입력하면 오디오가 입혀진, 그것도 입모양과 안면 움직임 등이 자연스럽게 반영된 비디오 영상을 생성하는데, 250시간 이상의 영상과 1억 5천만 개 이상의 이미지를 학습 데이터셋으로 사용했다고 합니다. 공개된 데모 영상이 너무 자연스러워서 깃헙 게시판에는 실행 코드를 공개하기 전까지는 못 믿겠다는 반응도 일부 있었습니다. ^^; 이 경우처럼, 모델 공개 때 깃헙 링크를 함께 공개하면서 실행코드가 없는 경우들을 가끔 볼 수 있죠. 하지만 대부분 언제쯤 공개하겠다는 언급이라도 적혀 있는데 EMO는 그게 없어서 약간 아쉽습니다.
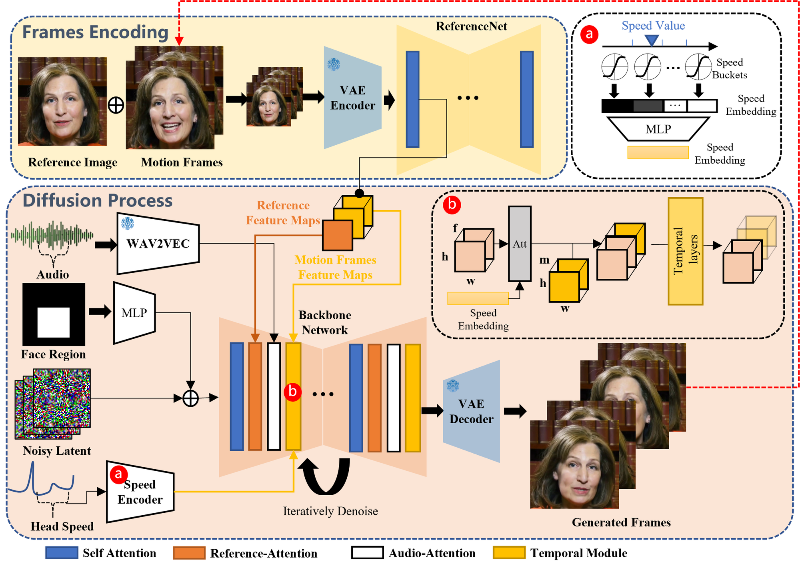
EMO는 얼굴 랜드마크나 3D 모델 방식을 사용하지 않고 직접 오디오 to 비디오 합성 방식을 적용했는데, 아무래도 전자의 방식이 연산량을 줄이는 장점이 있긴 하지만 표정의 풍부함과 자연스러움이 부족하다는 단점이 있었기 때문입니다. EMO의 네트워크 파이프라인은 프레임 인코딩과 확산과정으로 구성되는데, 프레임 인코딩 단계에서는 ReferenceNet을 통해 참조 이미지와 모션 프레임에서 Feature를 추출하고, 확산과정에서는 오디오, 얼굴 마스크, 멀티프레임의 노이즈 잠재입력, 머리 속도 정보를 백본 네트워크로 처리하여 캐릭터의 정체성을 보존하고 움직임 등을 안정적이고 자연스럽게 만들게 됩니다.
'AI 기술' 카테고리의 다른 글
| Genie : 2D 대화형 게임 생성 AI (1) | 2024.08.28 |
|---|---|
| MagicMan : 고품질의 인간 3D 재구성 모델 (0) | 2024.08.28 |
| DoubleTake : 기하학적 정보를 이용한 실시간 깊이 추정 (0) | 2024.08.28 |
| Phi-1.5 : 고품질 학습 데이터로 학습한 sLM (0) | 2024.08.27 |
| Multi-LoRA Switch & Composite : 복수 LoRA 통합의 새로운 방식 (0) | 2024.08.27 |



