

Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
Tags
- 생성형 AI
- 휴머노이드 로봇
- 오블완
- LLM
- tts
- LORA
- 확산 모델
- AI 기술
- 이미지 생성
- 우분투
- 시간적 일관성
- OpenAI
- 다국어 지원
- PYTHON
- TRANSFORMER
- 강화 학습
- ChatGPT
- OpenCV
- 메타
- 아두이노
- 딥러닝
- 실시간 렌더링
- 티스토리챌린지
- 트랜스포머
- 오픈AI
- 인공지능
- ubuntu
- AI
- 일론 머스크
- 오픈소스
Archives
- Today
- Total
AI 탐구노트
EAGLE : 비전 인코더 결합으로 MLLM의 시각 능력을 최적화한 모델 본문
비전 인코더를 결합하여 멀티모달 대형 언어 모델(MLLM)의 시각적 인식 능력을 최적화한 모델
EAGLE은 다양한 비전 인코더를 결합하여 멀티모달 대형 언어 모델(MLLM)의 시각적 인식 능력을 최적화한 모델입니다.
기존의 멀티모달 모델들은 주로 낮은 해상도 이미지 처리에 한정되었으며, 시각 인코더 선택 및 결합 전략에 대한 체계적인 비교와 세부적인 연구가 부족했고 이는 결과적으로 OCR 및 문서 분석과 같이 해상도가 민감한 작업에서 성능 저하를 초래했습니다.
EAGLE은 여러 비전 인코더의 조합과 고해상도 적응을 통해 이러한 문제를 해결하고자 합니다. 특히, 각 인코더의 시각적 토큰을 단순히 결합하는 방식이 복잡한 혼합 아키텍처만큼 효과적이며, 비전 인코더와 언어 토큰 간의 사전 정렬(Pre-Alignment)을 도입하여 모델의 일관성을 향상시켰습니다.
EAGLE 모델이 가지는 특징은 다음과 같습니다.
- 다양한 비전 인코더를 활용하여 MLLM의 성능을 극대화
- 간단한 채널 연결 방식으로 효율적이고 성능 높은 결합 전략 구현
- 비전 인코더를 해제(Unfreezing)하여 학습 성능 향상
- 사전 정렬 단계를 통해 비전 인코더와 언어 모델 간의 시너지 효과 극대화
- 고해상도 이미지 처리에 최적화

EAGLE의 탐색 파이프라인은 크게 고해상도 적응 및 학습 방법 탐색과 결합 전략 탐색의 두 주요 단계로 이뤄져 있습니다. 위의 그림은 다양한 실험과 비교를 통해 어떤 조합이 가장 효율적이고 성능이 좋은지를 찾는 과정을 시각적으로 설명하고 있습니다.
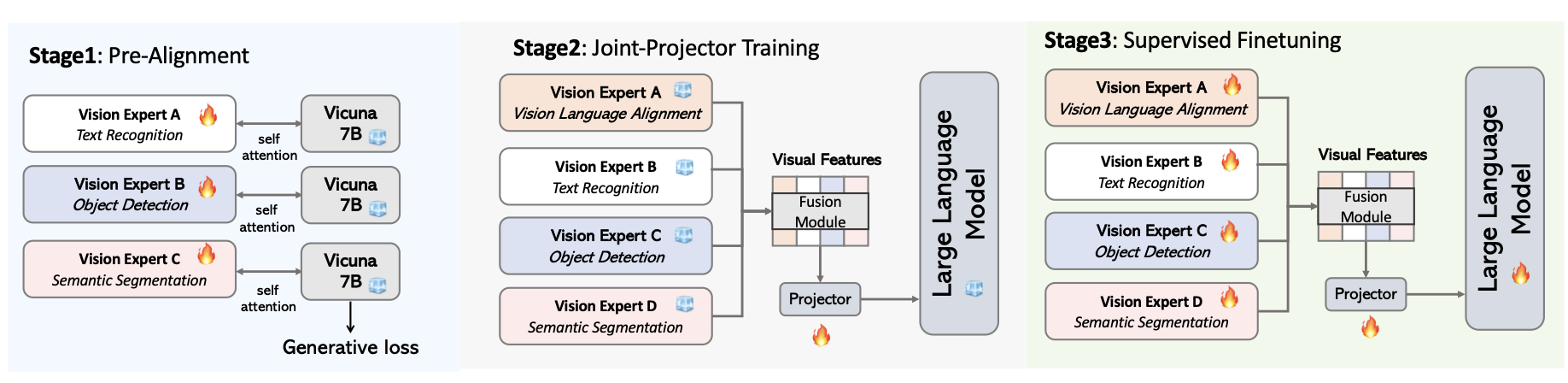
EAGLE의 아키텍처는 여러 비전 인코더로부터 추출된 시각적 특징들을 채널 단위로 결합하여 대형 언어 모델로 전달하는 방식입니다. 이 모델은 세 단계의 학습 절차를 통해 구축됩니다: 1) 개별 비전 인코더를 사전 정렬하고, 2) 이 인코더들 간의 결합을 최적화한 후, 3) 전체 모델을 미세 조정하여 최종 성능을 도출합니다.
'AI 기술' 카테고리의 다른 글
| PanoHead : 고품질 3D 머리 이미지 생성 모델 (0) | 2024.08.31 |
|---|---|
| SAHI : 다양한 스케일 객체를 효과적으로 감지하기 위한 기법 (0) | 2024.08.31 |
| DEVA : 다양한 비디오에서 객체를 추적할 수 있는 기법 (0) | 2024.08.30 |
| InterTrack : 인간-객체 상호작용을 추적하는 방법 (0) | 2024.08.30 |
| CogVideoX : 길이가 긴 일관된 동영상 생성 모델 (0) | 2024.08.29 |
'AI 기술' Related Articles
more



