

| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- 티스토리챌린지
- 메타
- 휴머노이드 로봇
- LORA
- 다국어 지원
- 확산 모델
- 딥러닝
- 인공지능
- ChatGPT
- TRANSFORMER
- 우분투
- OpenCV
- 실시간 렌더링
- 생성형 AI
- PYTHON
- 시간적 일관성
- ubuntu
- 일론 머스크
- 트랜스포머
- 오블완
- LLM
- 오픈소스
- tts
- AI 기술
- 아두이노
- OpenAI
- 오픈AI
- 이미지 생성
- 강화 학습
- AI
- Today
- Total
AI 탐구노트
ADD-IT: 사전학습된 확산 모델을 이용한 훈련 없는 객체 삽입 기술 본문

1.서론
디지털 콘텐츠 제작과 편집 기술의 발전으로 인해 이미지 편집 기술은 점점 더 중요해지고 있습니다. 특히, 텍스트 설명을 바탕으로 이미지에 객체를 삽입하는 기술은 컴퓨터 그래픽스, 자율주행 훈련 데이터 생성 등 다양한 산업 분야에서 활용 가능성이 높습니다. 그러나 이러한 작업은 단순히 객체를 추가하는 것 이상의 복잡성을 가집니다. 원본 이미지의 구조와 질감을 유지하면서도 자연스러운 위치에 객체를 배치하는 것이 관건입니다.
기존의 텍스트-이미지 확산 모델은 뛰어난 생성 능력을 보여주지만, 객체 삽입과 같은 특정 편집 작업에서는 여전히 한계가 있습니다. 이에 대한 해결책으로 NVIDIA와 텔아비브 대학교 연구팀은 훈련 없이 객체 삽입이 가능한 ADD-IT 모델을 제안했습니다. 이 기술은 사전 학습된 확산 모델의 다중 모달(attention) 메커니즘을 확장하여 이미지의 구조와 질감을 자연스럽게 유지하면서 새로운 객체를 삽입하는 데 중점을 둡니다.

2.본론
2.1.기존 방식의 문제점
기존의 텍스트-이미지 모델은 텍스트 또는 이미지의 특정 정보에 과도하게 의존하여 객체의 삽입 위치를 적절히 예측하지 못하거나 원본 이미지의 질감을 손상시키는 문제가 있었습니다. 이러한 문제는 특히 복잡한 장면에서 객체를 추가할 때 두드러지며, 잘못된 위치에 삽입되거나 시각적 일관성이 저하되는 결과를 초래했습니다.
2.2.접근 방식
ADD-IT은 기존 확산 모델의 다중 모달 어텐션 메커니즘을 확장하여 새로운 객체를 삽입합니다. 이를 통해 이미지의 구조를 유지하면서도 텍스트와 이미지 간의 조화를 이룹니다. 특히, 가중치 확장 어텐션과 주제 기반 잠재 블렌딩 기술을 사용하여 객체가 원본 이미지에 자연스럽게 융합되도록 합니다.
2.2.1.아키텍처
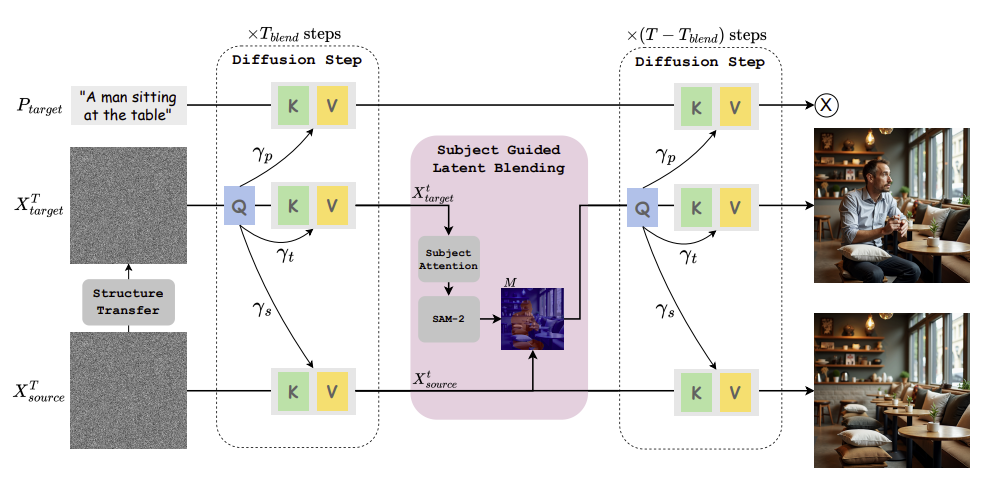
2.2.2.적용 세부 기술
- 가중치 확장 어텐션 (Weighted Extended Self-Attention)
기존의 다중모델 어텐션 메커니즘을 확장하여 이미지의 삽입 위치를 결정하는데, 이때 이미지의 원본 구조, 생성된 이미지, 텍스트 설명을 동시에 고려함으로써 객체가 삽입될 위치를 정확히 파악할 수 있습니다. - 구조 전이 (Structure Transfer)
원본 이미지의 구조를 새로운 이미지로 전이시켜 삽입되는 객체가 원본 이미지의 공간적 제약을 따르게 함으로써 일관된 장면 구성을 유지합니다. 이는 고유한 노이즈 프로세스를 통해 이루어지며, 시각적으로 자연스러운 결과를 제공합니다. - 주제 기반 잠재 블렌딩 (Subject-Guided Latent Blending)
삽입된 객체 주변의 질감과 디테일을 원본 이미지와 융합하여 시각적 일관성을 유지합니다. 이를 위해 마스크 생성 및 동적 블렌딩 기법을 활용합니다.
3. 결론
ADD-IT은 훈련 없이도 텍스트 기반의 객체 삽입에서 탁월한 성능을 발휘하며, 기존 방법론을 능가하는 결과를 제공합니다. 이 기술은 잘 활용되면 이미지 편집, 콘텐츠 제작, 그리고 자율주행을 위한 가상 데이터 생성과 같은 다양한 응용 분야에서 활용될 수 있을 것으로 생각됩니다.
4. 참고자료
Add-it 프로젝트 사이트
Add-it
Adding Object into images based on text instructions is a challenging task in semantic image editing, requiring a balance between preserving the original scene and seamlessly integrating the new object in a fitting location. Despite extensive efforts, exis
research.nvidia.com
Add-it 논문
https://arxiv.org/pdf/2411.07232
5. Q&A
Q. ADD-IT의 주요 장점은 무엇인가요?
훈련 없이도 텍스트 기반으로 자연스럽고 일관된 객체 삽입이 가능하다는 점입니다.
Q. ADD-IT은 어떤 기술적 요소를 사용하나요?
가중치 확장 어텐션, 구조 전이, 그리고 주제 기반 잠재 블렌딩 기술을 활용합니다.
Q. ADD-IT의 제약사항은 무엇인가요?
A3. 데이터 편향성과 현실 세계 이미지에 대한 성능 저하가 주요 제약사항입니다.
'AI 기술' 카테고리의 다른 글
| A Lightweight Face Detector via Bi-Stream Convolutional Neural Network and Vision Transformer (0) | 2024.11.21 |
|---|---|
| MagicQuill: 직관적인 이미지 편집 시스템을 향한 진화 (0) | 2024.11.19 |
| ReCapture: 사용자 제공 비디오를 활용한 생성적 카메라 컨트롤 (0) | 2024.11.18 |
| TRIA : Masked Token Modeling을 활용한 Zero-shot 드럼 비트 변환 (1) | 2024.11.17 |
| Moonshine : 실시간 음성 인식 모델의 새로운 접근 (3) | 2024.11.17 |



