

| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- OpenCV
- 일론 머스크
- PYTHON
- XAI
- 메타
- 우분투
- 티스토리챌린지
- AI
- ai 챗봇
- 확산 모델
- AI 기술
- 오블완
- gaussian splatting
- 시간적 일관성
- LLM
- 인공지능
- 트랜스포머
- ChatGPT
- 생성형AI
- 오픈소스
- 휴머노이드 로봇
- 자연어 처리
- 강화 학습
- tts
- LORA
- OpenAI
- 오픈AI
- 딥러닝
- 실시간 렌더링
- 멀티모달
- Today
- Total
AI 탐구노트
강의영상에서 슬라이드 파일 추출 방법 본문

1. 영상에서 슬라이드 추출하는 기술 소개
Youtube에서 논문 소개하는 영상들을 가끔 볼 수 있는데 PPT나 PDF 파일 링크를 알 수 없는 것들이 간혹 있습니다. 그래서, 영상에 나왔던 내용을 추출할 수 있으면 좋지 않을까 생각한 적이 있었는데 이미 그걸 하고 방법을 설명하는 곳이 있었죠. 아래 LearnOpenCV 사이트의 블로그 내용이 바로 그런 것입니다.
Video to Slides Converter using OpenCV Background Estimation
This blog post aims to build a simple video to slides converter application using Frame Differencing and Background Modeling techniques using OpenCV
learnopencv.com
이번 글에서는 위 블로그에서 소개하는 내용을 요약하고 실제로 동작시켜 보도록 하겠습니다.
2. 적용 기술
2.1. 배경 제거
여기에서는 다음과 같은 기술이 사용됩니다.
- 배경제거 (Background Subtraction) : 비디오에서 움직이는 전경 객체를 고정된 배경과 분리하는 기술입니다.
- 프레임 차분 (Frame Differecing)을 통한 배경 제거 : 연속된 두 프레임 간의 차이를 계산해서 움직임을 감지하는 방법입니다. 프레임간 큰 변화가 없는 영상에서 효과적입니다.
배경 제거 기법으로는 OpenCV가 제공하는 KNN 기반 방식과 GMG 배경 제거 방식이 사용됩니다.
KNN(K-Nearest Neighbors, K-최근접 이웃)
가까운 데이터 포인트 (K개의 이웃)을 기준으로 새로운 데이터의 결과를 예측하는 알고리즘으로 유클리드 거리(Euclidean Distance)를 이용하며, K개 이웃 중 가장 많이 등장하는 클래스(분류)나 K개의 이웃의 평균값(회귀)을 예측값으로 합니다.
GMG(GrabCut Mixture of Gaussians)
시간에 따라 변화하는 배경과 움직이는 전경 분리를 위해 MOG(Mixture of Gaussian)과 베이시안 세분화(Bayesian Segmentation) 기술을 이용합니다. 각 픽셀에 대한 다수의 가우시안 분포를 유지하며 배경, 전경을 모델링한 후 전경, 배경 픽셀에 대한 확률 분포를 계산해 결과를 세분화하는 방식으로 진행됩니다.
2.2. 슬라이드 추출
영상에서 슬라이드를 추출하는 워크플로우는 다음과 같습니다.
- 비디오 프레임을 회색조로 변환
- 프레임 차분이나 배경 제거를 통해 움직임 감지
- 움직임이 감지되지 않는 프레임을 슬라이드로 저장
- 저장된 슬라이드 이미지를 PDF로 변환
3. 테스트
3.1. 코드
실행 코드는 다음 링크에서 다운 받아서 압축을 해제합니다.
learnopencv/Build-a-Video-to-Slides-Converter-Application-using-the-Power-of-Background-Estimation-and-Frame-Differencing-in-Ope
Learn OpenCV : C++ and Python Examples. Contribute to spmallick/learnopencv development by creating an account on GitHub.
github.com
그 가운데 video_2_slides.py 파일을 옮기면 다음과 같습니다.
import os
import time
import sys
import cv2
import argparse
from frame_differencing import capture_slides_frame_diff
from post_process import remove_duplicates
from utils import resize_image_frame, create_output_directory, convert_slides_to_pdf
# -------------- Initializations ---------------------
FRAME_BUFFER_HISTORY = 15 # Length of the frame buffer history to model background.
DEC_THRESH = 0.75 # Threshold value, above which it is marked foreground, else background.
DIST_THRESH = 100 # Threshold on the squared distance between the pixel and the sample to decide whether a pixel is close to that sample.
MIN_PERCENT = 0.15 # %age threshold to check if there is motion across subsequent frames
MAX_PERCENT = 0.01 # %age threshold to determine if the motion across frames has stopped.
# ----------------------------------------------------
def capture_slides_bg_modeling(video_path, output_dir_path, type_bgsub, history, threshold, MIN_PERCENT_THRESH, MAX_PERCENT_THRESH):
print(f"Using {type_bgsub} for Background Modeling...")
print('---'*10)
if type_bgsub == 'GMG':
bg_sub = cv2.bgsegm.createBackgroundSubtractorGMG(initializationFrames=history, decisionThreshold=threshold)
elif type_bgsub == 'KNN':
bg_sub = cv2.createBackgroundSubtractorKNN(history=history, dist2Threshold=threshold, detectShadows=False)
capture_frame = False
screenshots_count = 0
# Capture video frames.
cap = cv2.VideoCapture(video_path)
if not cap.isOpened():
print('Unable to open video file: ', video_path)
sys.exit()
start = time.time()
# Loop over subsequent frames.
while cap.isOpened():
ret, frame = cap.read()
if not ret:
break
# Create a copy of the original frame.
orig_frame = frame.copy()
# Resize the frame keeping aspect ratio.
frame = resize_image_frame(frame, resize_width=640)
# Apply each frame through the background subtractor.
fg_mask = bg_sub.apply(frame)
# Compute the percentage of the Foreground mask."
p_non_zero = (cv2.countNonZero(fg_mask) / (1.0 * fg_mask.size)) * 100
# %age of non-zero pixels < MAX_PERCENT_THRESH, implies motion has stopped.
# Therefore, capture the frame.
if p_non_zero < MAX_PERCENT_THRESH and not capture_frame:
capture_frame = True
screenshots_count += 1
png_filename = f"{screenshots_count:03}.png"
out_file_path = os.path.join(output_dir_path, png_filename)
print(f"Saving file at: {out_file_path}")
cv2.imwrite(out_file_path, orig_frame)
# p_non_zero >= MIN_PERCENT_THRESH, indicates motion/animations.
# Hence wait till the motion across subsequent frames has settled down.
elif capture_frame and p_non_zero >= MIN_PERCENT_THRESH:
capture_frame = False
end_time = time.time()
print('***'*10,'\n')
print("Statistics:")
print('---'*10)
print(f'Total Time taken: {round(end_time-start, 3)} secs')
print(f'Total Screenshots captured: {screenshots_count}')
print('---'*10,'\n')
# Release Video Capture object.
cap.release()
if __name__ == "__main__":
parser = argparse.ArgumentParser(description="This script is used to convert video frames into slide PDFs.")
parser.add_argument("-v", "--video_file_path", help="Path to the video file", type=str)
parser.add_argument("-o", "--out_dir", default = 'output_results', help="Path to the output directory", type=str)
parser.add_argument("--type", help = "type of background subtraction to be used", default = 'GMG',
choices=['Frame_Diff', 'GMG', 'KNN'], type=str)
parser.add_argument("--no_post_process", action="store_true", default=False, help="flag to apply post processing or not")
parser.add_argument("--convert_to_pdf", action="store_true", default=False, help="flag to convert the entire image set to pdf or not")
args = parser.parse_args()
video_path = args.video_file_path
output_dir_path = args.out_dir
type_bg_sub = args.type
output_dir_path = create_output_directory(video_path, output_dir_path, type_bg_sub)
if type_bg_sub.lower() == 'frame_diff':
capture_slides_frame_diff(video_path, output_dir_path)
else:
if type_bg_sub.lower() == 'gmg':
thresh = DEC_THRESH
elif type_bg_sub.lower() == 'knn':
thresh = DIST_THRESH
capture_slides_bg_modeling(video_path, output_dir_path, type_bgsub=type_bg_sub,
history=FRAME_BUFFER_HISTORY, threshold=thresh,
MIN_PERCENT_THRESH=MIN_PERCENT, MAX_PERCENT_THRESH=MAX_PERCENT)
# Perform post-processing using difference hashing technique to remove duplicate slides.
if not args.no_post_process:
remove_duplicates(output_dir_path)
if args.convert_to_pdf:
convert_slides_to_pdf(video_path, output_dir_path)
3.2. 실행 및 결과 확인
# 필요한 패키지 설치 - opencv-contrib-python 필요한데 오류나면 --force-reinstall 이용해서 재설치
$ pip install -r requirements.txt
# 실행 - 샘플용 영상은 포함되어 있음
$ python video_2_slides.py -v ./sample_vids/Neural_Networks_Overview.mp4 -o output_results --type GMG --convert_to_pdf
실행해 보면 다음과 같이 진행 현황을 볼 수 있습니다.
Output directory created...
Path: output_results\Neural_Networks_Overview\GMG
******************************
Using GMG for Background Modeling...
------------------------------
...
Saving file at: output_results\Neural_Networks_Overview\GMG\134.png
Saving file at: output_results\Neural_Networks_Overview\GMG\135.png
Saving file at: output_results\Neural_Networks_Overview\GMG\136.png
Saving file at: output_results\Neural_Networks_Overview\GMG\137.png
******************************
Statistics:
------------------------------
Total Time taken: 367.749 secs
Total Screenshots captured: 137
------------------------------
--------------- Finding similar files ---------------
...
Duplicate file: 129.png
Duplicate file: 132.png
Duplicate file: 137.png
Total duplicate files: 73
--------------------------------------------------
Removing duplicates...
All duplicates removed!
******************************
Output PDF Path: output_results\Neural_Networks_Overview\GMG\Neural_Networks_Overview.pdf
Converting captured slide images to PDF...
PDF Created!
******************************
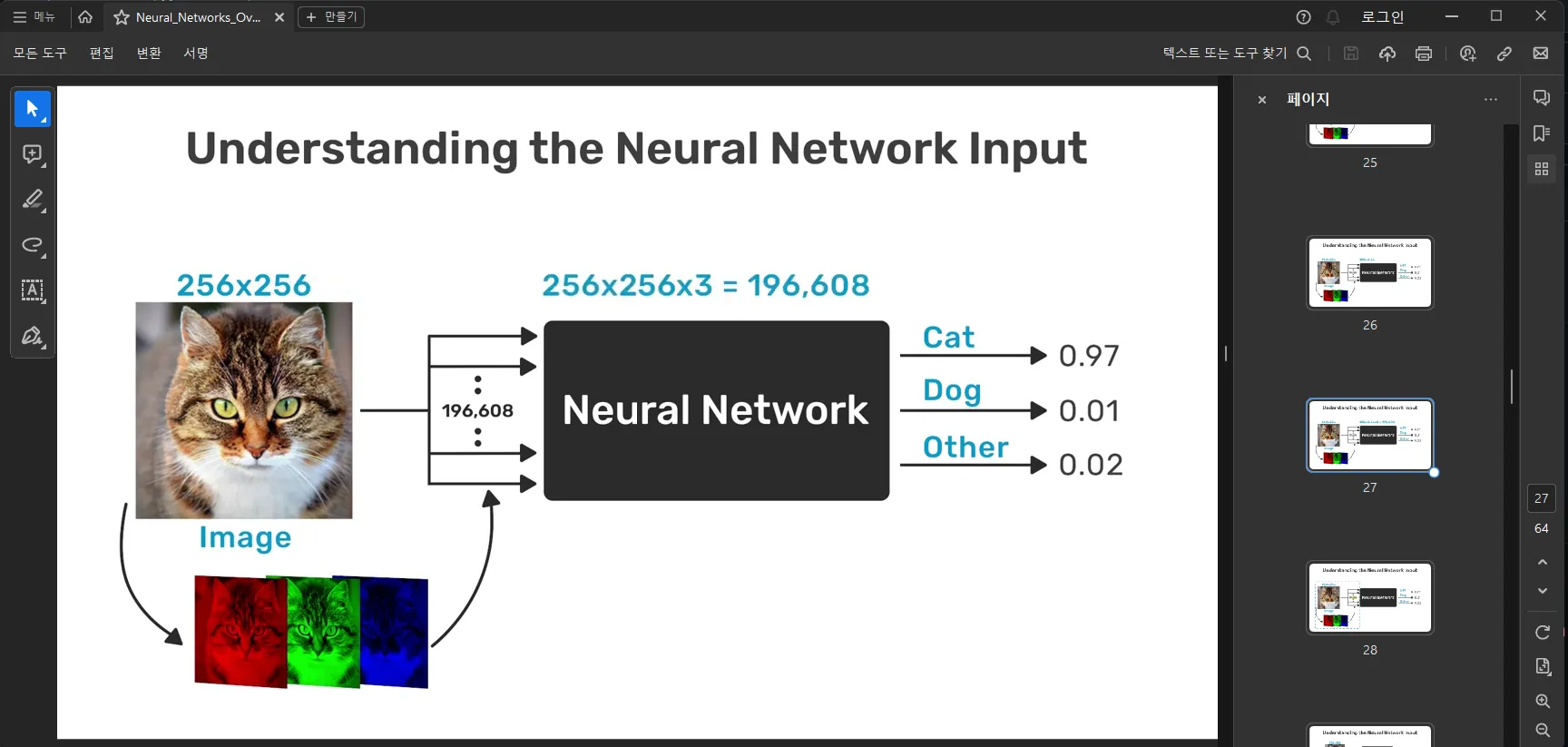
생성이 완료되면 GMG 폴더에는 추출된 이미지가 저장되며, 이들을 합쳐서 하나의 PDF 파일로 생성하게 됩니다.
4. 후기
이번 글에서는 강의 비디오나 논문 소개 영상 등에서 슬라이드를 자동으로 추출하는 방법을 테스트 해 봤습니다. 블로그에서 소개한 바대로 손쉽게 이뤄지는데 잘만 활용하면 긴 전체 영상을 유튜브에서 보는 것 대신 들고 다닐 수 있는 스터디 자료로 만들 수 있을 것 같습니다. 한가지 더 나아가면 꼭 슬라이드가 아니더라도 영상에서 변화가 거의 없는 영역을 제거해서 전체 내용에 대한 요약본을 만드는 그런 용도로도 활용할 수 있지 않을까 생각됩니다. 그냥 떠오른 생각이지만요... ^^
'DIY 테스트' 카테고리의 다른 글
| 카메라 영상을 이용한 침입감지 테스트 (8) | 2024.11.12 |
|---|---|
| FaceFusion : 안면 얼굴 교체를 손쉽게 해주는 AI 소프트웨어 (4) | 2024.11.12 |
| 사진 속의 얼굴 표정을 편집하는 솔루션 테스트 (4) | 2024.11.07 |
| OpenCV를 이용한 물체 크기 측정 (2) | 2024.11.06 |
| 이미지, 영상 복원 테스트 (6) | 2024.11.05 |



