

| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- OpenAI
- 일론 머스크
- LLM
- 시간적 일관성
- ChatGPT
- 다국어 지원
- 인공지능
- 메타
- 강화 학습
- 생성형AI
- 트랜스포머
- 확산 모델
- 우분투
- 멀티모달
- 티스토리챌린지
- 코딩
- AI 기술
- 휴머노이드 로봇
- PYTHON
- 딥러닝
- OpenCV
- LORA
- ubuntu
- ai 챗봇
- 오블완
- 오픈AI
- tts
- XAI
- AI
- 오픈소스
- Today
- Total
AI 탐구노트
Voila: 실시간 자율형 음성 AI를 위한 새로운 음성-언어 모델의 등장 본문

우리가 인공지능과 대화할 때 가장 흔히 떠올리는 모습은 음성 비서입니다. 예를 들어 '헤이 시리' 또는 '오케이 구글'과 같은 호출어로 AI를 부르고 질문을 던지면, AI가 이에 반응해 답을 제공하죠. 하지만 이러한 상호작용은 대부분 사용자의 명령에만 반응하는 ‘반응형 시스템’입니다. 인간처럼 먼저 말을 걸거나 감정을 파악해 적절한 반응을 하는 AI는 아직까지 상상 속에만 존재했죠. 최근 들어 인공지능 기술은 이러한 제약을 넘어서려는 시도를 보이고 있으며, 이 글에서 소개할 'Voila'는 그 최전선에 있는 기술입니다.
‘Voila’는 음성 기반의 실시간 대화를 가능하게 하며, 사용자의 감정이나 말투, 대화 흐름까지 고려하여 더욱 자연스럽고 자율적인 대화를 시도하는 새로운 모델입니다. 단순히 질문에 답하는 수준을 넘어, 사용자가 말하기 전에 먼저 상황을 파악하고 말을 걸거나, 감정을 인지하여 위로의 말을 건네는 등의 능동적인 기능까지 제공합니다. 이러한 기술은 영화 Her에 나오는 AI처럼 인간과 감정적인 유대감을 형성하는 것을 목표로 하고 있습니다.
VOILA
1) 기존 방식의 문제점
기존의 음성 AI는 크게 세 단계로 구성된 파이프라인 구조를 따릅니다. 먼저 사람의 말을 텍스트로 바꾸는 자동 음성 인식(ASR), 그 텍스트를 이해하고 답변을 생성하는 언어 모델(LLM), 마지막으로 답변을 음성으로 바꾸는 텍스트-음성 변환(TTS)이죠. 이 방식은 기술적으로는 안정적이지만 다음과 같은 문제점이 있습니다.
- 지연 시간 : 각 단계마다 처리 시간이 걸려 실제 대화처럼 자연스럽게 주고받기엔 시간이 오래 걸립니다.
- 감정 및 말투 손실 : 음성을 텍스트로 변환하는 과정에서 감정, 억양, 배경음 등 중요한 음성적 정보가 사라집니다.
- 기계적인 대화 흐름 : 차례를 기다려야만 말할 수 있는 구조로 인해 자연스러운 인간 대화처럼 느껴지지 않습니다.

2) 접근 방식
Voila는 기존 파이프라인 방식에서 벗어나 종단 간(end-to-end) 방식의 음성-언어 모델을 채택했습니다. 이는 음성을 텍스트로 바꾸지 않고 음성 그대로를 처리하고 생성할 수 있도록 설계된 구조입니다. 이 방식은 다음과 같은 장점이 있습니다.
- 낮은 지연 시간 : 전체 반응 시간이 195밀리초로 인간 평균 반응 시간보다도 빠릅니다.
- 풍부한 음성 정보 보존 : 억양, 감정, 말투 등의 정보가 보존되어 자연스러운 응답이 가능해집니다.
- 동시 대화(Full-duplex) 지원 : 사용자와 AI가 동시에 말할 수 있는 구조로 인간과 같은 대화를 구현합니다.
특히 Voila-autonomous 모델은 사용자의 음성과 Voila의 응답을 동시에 처리하는 이중 스트림 구조를 사용해 더욱 유연한 상호작용을 가능하게 합니다.
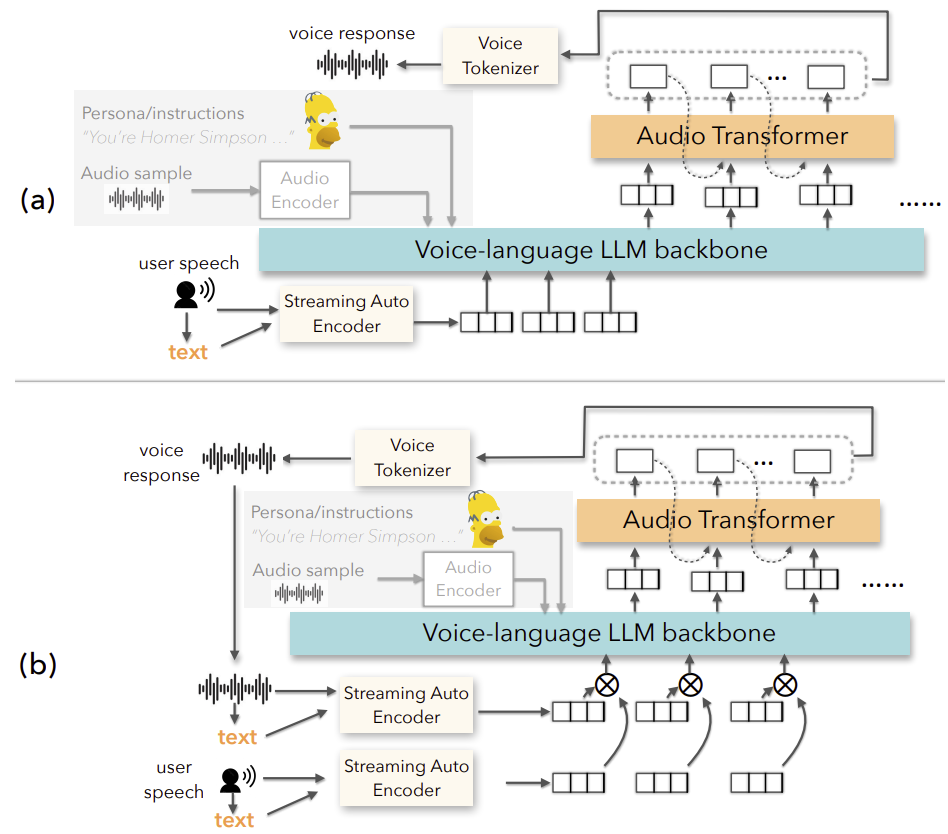
3) 세부 적용 기술
1️⃣ 다중 스케일 트랜스포머(Multi-scale Transformer)
Voila는 언어 처리와 음성 생성을 위해 각각 다른 트랜스포머 구조를 사용합니다. 언어적 의미는 LLM 백본이 처리하고, 음성적 요소는 별도의 오디오 트랜스포머가 담당합니다. 이를 통해 의미와 감정을 동시에 잘 표현할 수 있습니다.
2️⃣ 음성 토크나이저(Voice Tokenizer)
연속된 음성 데이터를 ‘음성 토큰’으로 변환하는 기술입니다. Voila는 의미 정보를 담은 토큰(semantic token)과 음향 정보를 담은 토큰(acoustic token)을 구분하여 처리하며, 이 두 가지를 함께 예측하여 더 풍부하고 자연스러운 음성을 생성할 수 있습니다.
3️⃣ 텍스트-음성 정렬 기술(Text-Audio Alignment)
Voila는 텍스트와 음성을 교차 정렬하여 단어 단위로 음성 토큰을 정렬하는 구조를 사용합니다. 예: 'Hello' → 'Hello' + <audio token>. 이 방식은 텍스트와 음성의 싱크를 정확하게 맞춰 감정과 억양이 담긴 말하기를 가능하게 합니다

4️⃣ 음성 커스터마이징 (Voice Customization)
사용자는 10초짜리 음성만으로 자신만의 음성을 AI에 학습시켜 사용할 수 있습니다. 영화 캐릭터나 유명인의 목소리를 입힌 AI 캐릭터도 만들 수 있으며, 이를 통해 100만 개 이상의 사전 제작된 음성을 제공합니다.
4) 제약사항
- 아직까지 Voila는 영어 중심으로 훈련된 비중이 높으며, 한국어와 같은 다른 언어에 대해선 향후 개선이 필요합니다.
- 실시간 감정 인식과 응답의 정확도는 사용 환경에 따라 다를 수 있으며, 민감한 대화 주제에서는 주의가 요구됩니다.
Voila는 기존의 파이프라인 기반 음성 AI의 한계를 극복하고, 실시간 자율형 음성 AI로 나아가는 전환점이 될 수 있는 모델입니다. 그리고, 사용자와의 자연스러운 상호작용, 감정 표현, 빠른 반응 속도, 다양한 커스터마이징 기능 등은 앞으로 음성 AI의 활용 범위를 더욱 넓혀줄 것으로 기대됩니다. 특히, 제약사항이 개선된다면 교육, 상담, 게임, 고객 서비스 등 다양한 산업에서 인간과 감정적으로 연결되는 AI 파트너로 자리 잡을 수 있을 것입니다.
참고자료
- 사이트) VOILA 프로젝트 (링크)
- 논문) Voila: Voice-Language Foundation Models for Real-Time Autonomous Interaction and Voice Role-Play (링크)
- 코드) VOILA github 저장소 (링크)
- 데모) VOILA 허깅페이스 데모 (링크)
Q&A
Q. Voila는 기존 음성 AI 시스템과 어떤 점이 다른가요?
Voila는 텍스트 기반의 반응형 시스템이 아닌, 음성 입력을 그대로 처리하고, 감정과 억양을 유지한 음성 출력이 가능한 종단 간 모델입니다.
Q. Voila는 어떤 방식으로 음성을 이해하고 생성하나요?
음성 데이터를 의미와 음향으로 나눈 후, 이를 각각 처리해 더욱 정교한 음성 응답을 만들어냅니다. 텍스트-음성 정렬 기술로 말과 목소리의 싱크도 맞춥니다.
Q. 사용자 목소리를 AI에 적용하는 것도 가능한가요?
네, 몇 초짜리 음성 샘플만 있으면 해당 목소리를 복제한 AI 음성을 만들 수 있습니다. 이를 통해 자신만의 캐릭터 음성을 만들 수도 있습니다.
'AI 기술' 카테고리의 다른 글
| 자신만의 폰트 제작 - 1) 폰트 제작 과정과 필요성 (0) | 2025.05.09 |
|---|---|
| VLM (Vision Langunage Model) 정리 (4) | 2025.05.08 |
| T2I-R1 : 2단계 (Semantic/Token) 레벨 CoT로 이미지 생성 성능을 강화 (0) | 2025.05.06 |
| Spatial Speech Translation : 실시간+감정표현이 가능한 공간 인식 기반 다중 화자 음성 번역 기술 (0) | 2025.05.05 |
| LiveCC : 실시간 음성 전사로 대규모 학습하는 비디오 LLM (1) | 2025.04.30 |



